Production RAG: Fix What Breaks After the Demo (2026)
Production RAG System Design
There's a gap between a RAG system that works in a Jupyter notebook and one that serves 10,000 requests per day with 99.5% uptime. Most tutorials help you cross the first milestone. This guide is about the second.
The production failure modes look different from development failures. In development, you test with 10 curated questions and iterate until they look right. In production, you discover that 20% of user queries are phrased in ways you never anticipated, your vector database connection pool is exhausted during traffic spikes, your prompt is hitting the token limit for certain document types, and your indexing pipeline silently stopped updating three days ago because a PDF format changed.
Production RAG is an operational system, not just an AI feature. It needs the same rigor you'd apply to any backend service: monitoring, caching, graceful degradation, and a deployment pipeline. This guide covers the architectural decisions that make the difference.
For the foundational architecture, see the RAG Architecture Guide.
Concept Overview
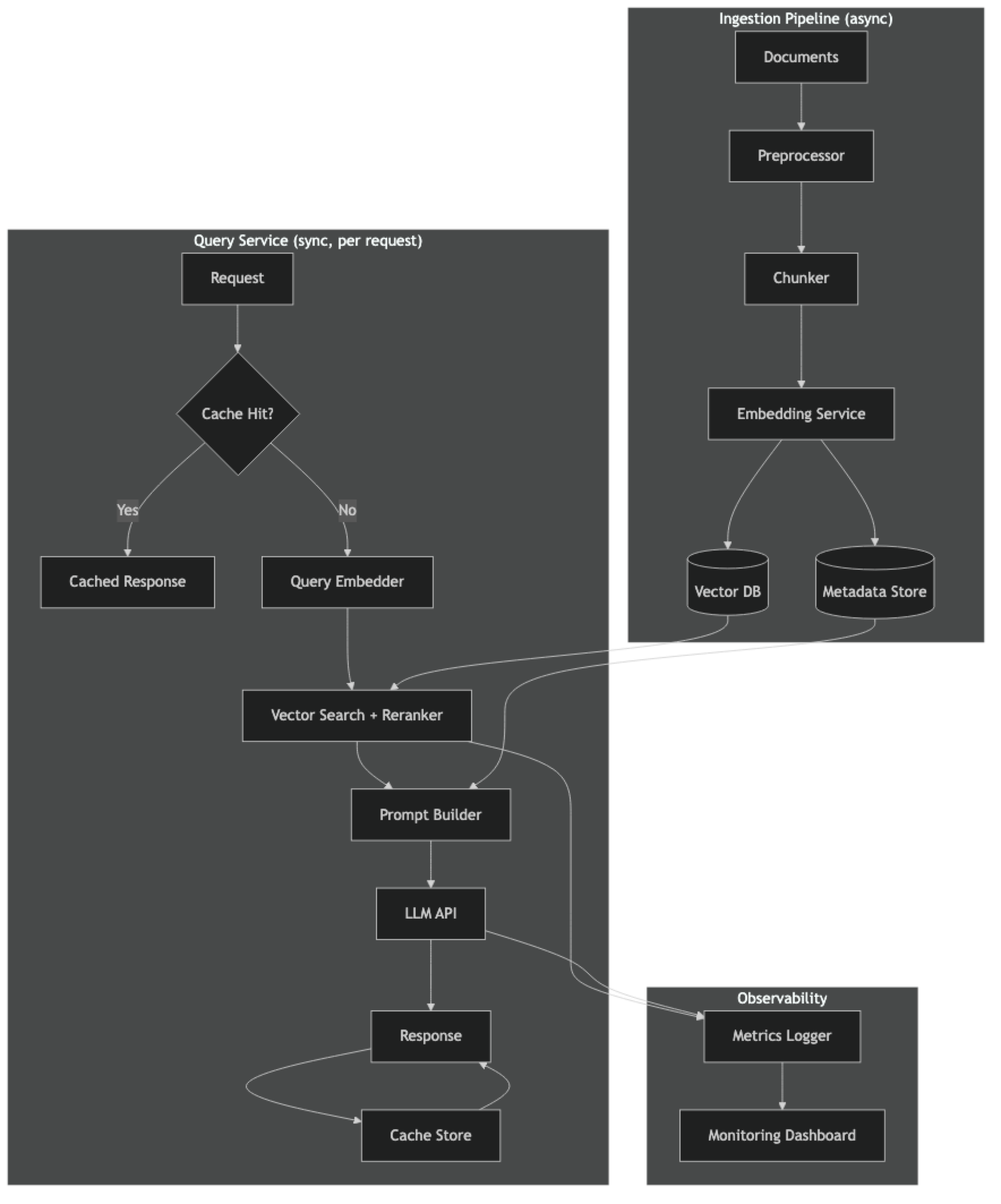
A production RAG system has five operational concerns beyond the basic pipeline:
- Reliability — the system serves requests even when components fail
- Latency — responses arrive within user-acceptable timeframes (typically < 3s)
- Cost — embedding and LLM API costs scale predictably with traffic
- Freshness — the knowledge base reflects current documents without service interruption
- Observability — you can see what's happening and diagnose failures
Each concern requires deliberate design. None of them come for free.
How It Works
Implementation Example
Production FastAPI Service
# app.py — production RAG service with caching, logging, and graceful degradation
import os
import time
import hashlib
import logging
from contextlib import asynccontextmanager
from typing import Optional
import redis
from fastapi import FastAPI, HTTPException, Request
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_chroma import Chroma
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
# ── Configuration ────────────────────────────────────────────────────
logging.basicConfig(level=logging.INFO, format="%(asctime)s %(levelname)s %(message)s")
logger = logging.getLogger("rag-service")
OPENAI_API_KEY = os.environ["OPENAI_API_KEY"]
REDIS_URL = os.environ.get("REDIS_URL", "redis://localhost:6379")
CHROMA_DIR = os.environ.get("CHROMA_DIR", "./chroma_db")
CACHE_TTL_SECONDS = int(os.environ.get("CACHE_TTL", "3600"))
LLM_MODEL = os.environ.get("LLM_MODEL", "gpt-4o-mini")
EMBEDDING_MODEL = os.environ.get("EMBEDDING_MODEL", "text-embedding-3-small")
# ── Global state (loaded once at startup) ────────────────────────────
class AppState:
vectorstore: Optional[Chroma] = None
rag_chain = None
retriever = None
redis_client: Optional[redis.Redis] = None
startup_time: float = 0
state = AppState()
# ── Startup / shutdown lifecycle ─────────────────────────────────────
@asynccontextmanager
async def lifespan(app: FastAPI):
logger.info("Starting RAG service...")
start = time.time()
# Load vector store (never re-index on startup)
state.vectorstore = Chroma(
persist_directory=CHROMA_DIR,
embedding_function=OpenAIEmbeddings(model=EMBEDDING_MODEL),
collection_name="production_docs"
)
chunk_count = state.vectorstore._collection.count()
logger.info(f"Loaded {chunk_count} vectors from {CHROMA_DIR}")
if chunk_count == 0:
logger.error("Vector store is empty — check indexing pipeline")
raise RuntimeError("Vector store empty")
# Build LCEL RAG chain
llm = ChatOpenAI(model=LLM_MODEL, temperature=0, request_timeout=30)
state.retriever = state.vectorstore.as_retriever(
search_type="mmr",
search_kwargs={"k": 5, "fetch_k": 20}
)
prompt = ChatPromptTemplate.from_messages([
("system", """Answer the question based ONLY on the provided context.
If the context is insufficient, say: "I do not have that information in my knowledge base."
Context:
{context}"""),
("human", "{question}"),
])
def format_docs(docs):
return "\n\n---\n\n".join(d.page_content for d in docs)
state.rag_chain = (
{"context": state.retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# Connect to Redis cache
try:
state.redis_client = redis.from_url(REDIS_URL, decode_responses=True)
state.redis_client.ping()
logger.info("Redis cache connected")
except redis.RedisError as e:
logger.warning(f"Redis unavailable — running without cache: {e}")
state.redis_client = None
state.startup_time = time.time() - start
logger.info(f"Service ready in {state.startup_time:.2f}s")
yield
# Cleanup
logger.info("Shutting down RAG service")
app = FastAPI(title="Production RAG API", lifespan=lifespan)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_methods=["POST", "GET"],
allow_headers=["*"]
)
# ── Request/Response models ───────────────────────────────────────────
class QueryRequest(BaseModel):
question: str
filters: Optional[dict] = None # optional metadata filters
use_cache: bool = True
class Source(BaseModel):
file: str
page: str
class QueryResponse(BaseModel):
answer: str
sources: list[Source]
cached: bool
latency_ms: int
# ── Cache helpers ─────────────────────────────────────────────────────
def cache_key(question: str, filters: dict = None) -> str:
payload = f"{question}:{filters}"
return f"rag:v1:{hashlib.md5(payload.encode()).hexdigest()}"
def get_cached_response(key: str) -> Optional[dict]:
if not state.redis_client:
return None
try:
import json
cached = state.redis_client.get(key)
return json.loads(cached) if cached else None
except (redis.RedisError, ValueError):
return None
def cache_response(key: str, response: dict):
if not state.redis_client:
return
try:
import json
state.redis_client.setex(key, CACHE_TTL_SECONDS, json.dumps(response))
except redis.RedisError:
pass # cache failure is non-fatal
# ── Main query endpoint ───────────────────────────────────────────────
@app.post("/v1/query", response_model=QueryResponse)
async def query(request: QueryRequest, http_request: Request):
if not request.question.strip():
raise HTTPException(status_code=400, detail="Question cannot be empty")
start = time.time()
request_id = http_request.headers.get("X-Request-ID", "unknown")
logger.info(f"[{request_id}] Query: {request.question[:100]}")
# Check cache
key = cache_key(request.question, request.filters)
if request.use_cache:
cached = get_cached_response(key)
if cached:
latency = int((time.time() - start) * 1000)
logger.info(f"[{request_id}] Cache hit — {latency}ms")
return QueryResponse(
answer=cached["answer"],
sources=[Source(**s) for s in cached["sources"]],
cached=True,
latency_ms=latency
)
# Run RAG chain
try:
retrieved_docs = state.retriever.invoke(request.question)
answer = state.rag_chain.invoke(request.question)
except Exception as e:
logger.error(f"[{request_id}] RAG chain error: {e}")
raise HTTPException(status_code=503, detail="Query processing failed — please retry")
sources = [
Source(
file=doc.metadata.get("source", "unknown"),
page=str(doc.metadata.get("page", "?"))
)
for doc in retrieved_docs
]
latency = int((time.time() - start) * 1000)
logger.info(f"[{request_id}] Answered in {latency}ms | sources: {[s.file for s in sources]}")
# Store in cache
cache_response(key, {
"answer": answer,
"sources": [s.dict() for s in sources]
})
return QueryResponse(
answer=answer,
sources=sources,
cached=False,
latency_ms=latency
)
# ── Health and metrics ─────────────────────────────────────────────────
@app.get("/health")
async def health():
chunk_count = state.vectorstore._collection.count() if state.vectorstore else 0
cache_ok = False
if state.redis_client:
try:
state.redis_client.ping()
cache_ok = True
except redis.RedisError:
pass
return {
"status": "healthy" if chunk_count > 0 else "degraded",
"chunks_indexed": chunk_count,
"cache_connected": cache_ok,
"model": LLM_MODEL,
"startup_time_seconds": round(state.startup_time, 2)
}Async Indexing Pipeline
# indexer.py — run as a separate service, not in the query path
import os
import time
import hashlib
import logging
from pathlib import Path
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
logger = logging.getLogger("rag-indexer")
def compute_file_hash(filepath: str) -> str:
"""Compute SHA256 of file content for change detection."""
with open(filepath, "rb") as f:
return hashlib.sha256(f.read()).hexdigest()
def incremental_index(
docs_dir: str,
persist_dir: str,
state_file: str = "./indexer_state.json"
) -> dict:
"""
Index only new or changed documents.
Returns stats dict.
"""
import json
# Load previous state
state_path = Path(state_file)
prev_state = json.loads(state_path.read_text()) if state_path.exists() else {}
# Scan current files
docs_path = Path(docs_dir)
current_files = {str(p): compute_file_hash(str(p)) for p in docs_path.glob("**/*.pdf")}
# Find changed or new files
new_or_changed = {
path: hash_val for path, hash_val in current_files.items()
if prev_state.get(path) != hash_val
}
# Find deleted files
deleted = set(prev_state.keys()) - set(current_files.keys())
logger.info(f"New/changed: {len(new_or_changed)}, deleted: {len(deleted)}, unchanged: {len(current_files) - len(new_or_changed)}")
if not new_or_changed and not deleted:
logger.info("No changes detected — skipping indexing")
return {"indexed": 0, "deleted": 0}
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vs = Chroma(
persist_directory=persist_dir,
embedding_function=embeddings,
collection_name="production_docs"
)
# Delete chunks from changed/deleted documents
for path in list(new_or_changed.keys()) + list(deleted):
try:
# Find and delete all chunks from this document
existing = vs.get(where={"source": path})
if existing["ids"]:
vs.delete(ids=existing["ids"])
logger.info(f"Deleted {len(existing['ids'])} chunks from {path}")
except Exception as e:
logger.warning(f"Error deleting {path}: {e}")
# Index new/changed documents
splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=64)
indexed_count = 0
for path in new_or_changed:
try:
loader = PyPDFLoader(path)
pages = loader.load()
for page in pages:
page.metadata["source"] = path
chunks = splitter.split_documents(pages)
vs.add_documents(chunks)
indexed_count += len(chunks)
logger.info(f"Indexed {len(chunks)} chunks from {path}")
except Exception as e:
logger.error(f"Failed to index {path}: {e}")
# Save new state
state_path.write_text(json.dumps(current_files))
return {"indexed": indexed_count, "deleted": len(deleted)}
if __name__ == "__main__":
logging.basicConfig(level=logging.INFO)
stats = incremental_index("./docs", "./chroma_db")
logger.info(f"Indexing complete: {stats}")Monitoring with Structured Logging
# metrics.py — structured logging for monitoring dashboards
import time
import json
import logging
from dataclasses import dataclass, asdict
@dataclass
class RAGMetric:
"""Structured metric for a single RAG query."""
request_id: str
question_length: int
retrieval_latency_ms: int
llm_latency_ms: int
total_latency_ms: int
chunks_retrieved: int
cached: bool
answer_length: int
sources: list[str]
error: str = None
def log_metric(metric: RAGMetric, logger: logging.Logger):
"""Emit metric as structured JSON for log aggregation (Datadog, CloudWatch, etc.)."""
logger.info(json.dumps({"event": "rag_query", **asdict(metric)}))Best Practices
Separate ingestion from serving. The indexing pipeline and the query API are operationally different systems — different scaling requirements, different failure modes, different update cycles. Run them as separate processes or services.
Cache at the query level. Many production RAG systems see 20–40% of queries as near-duplicates (slightly rephrased versions of common questions). A simple Redis cache with a 1-hour TTL dramatically reduces API costs and latency for these queries.
Never re-index on startup. Loading the persisted vector store takes under a second. Indexing from documents takes minutes and costs money. The service startup path should only load; never index.
Implement incremental indexing. Hash source files and track which files have changed since the last index run. Re-index only changed files. This makes document updates fast and cheap.
Set explicit LLM timeouts. LLM API calls can hang for 30+ seconds under load. Set request_timeout=30 on your LLM client and catch the timeout to return a graceful error response.
Use structured logging. Every RAG request should emit a structured log with: request ID, retrieval latency, LLM latency, chunk count, cache status, and sources. This is your primary debugging surface in production.
Common Mistakes
Storing the vector store on ephemeral disk. If your Docker container or cloud instance restarts, an ephemeral volume loses the index. Use a persistent volume or a managed vector database for production.
No cache invalidation strategy. Caching answers is great until a document changes and cached answers become wrong. Implement a cache invalidation event that fires when documents are updated.
Ignoring connection pooling. Vector database connections are not free to establish. Configure a connection pool sized to your concurrency requirements. ChromaDB and Qdrant both support connection pooling.
Single point of failure on the LLM. If OpenAI is having an incident, your entire RAG service goes down. Build a fallback: return cached results when available, or a degraded "I'm temporarily unable to answer" response when the LLM is unreachable.
No document update audit trail. In production, you need to know when each document was indexed, what version was indexed, and who triggered the indexing. Without this, diagnosing "why is the answer wrong" after a document update is very difficult.
FAQ
What vector database should I use in production? For self-hosted: Qdrant — excellent performance, filtering, and Rust-based reliability. For managed: Pinecone for simplicity, Weaviate for complex filtering needs. ChromaDB is excellent for development but not recommended for high-traffic production (no distributed mode, no built-in replication).
How do I handle RAG system downtime for document updates? Maintain two vector stores (blue/green). Index updates to the inactive store while the active store serves traffic. Swap the retriever pointer when indexing is complete. This gives zero-downtime document updates with no user-visible disruption.
What is a realistic latency target for production RAG? P50 under 1.5s, P95 under 3s is achievable for most setups. Latency breakdown: query embedding ~50ms, vector search ~100ms, LLM generation 600ms–2s, reranking ~100ms. Redis caching cuts P50 to under 10ms for repeated queries.
How do I handle PII in the knowledge base? Run PII detection (spaCy, AWS Comprehend, or Azure PII detection) on documents before indexing. Redact or pseudonymize sensitive fields. Store PII classification in chunk metadata and enforce access control at retrieval time using metadata filters.
Should I expose the RAG API directly to end users? Not without rate limiting and authentication. Add a token-bucket rate limiter per user, API key authentication, and input validation. A raw RAG API exposed to the internet will be scraped, prompt-injected, and abused quickly.
How do I know if my production RAG pipeline is degrading over time? Track three metrics per query: retrieval hit rate (do retrieved chunks contain the expected information?), faithfulness (does the answer stay within the retrieved context?), and answer latency. Alert if faithfulness drops below 0.85 or hit rate drops more than 10% week-over-week. This usually signals a document update that invalidated cached chunks.
How do I scale the indexing pipeline for thousands of documents?
Process documents in parallel with a task queue (Celery + Redis, or AWS SQS). Use batch embedding calls (the OpenAI embedding API supports up to 2,048 inputs per call). Store a file hash in a database and only re-index when the hash changes. For very large collections (>1M chunks), consider a dedicated embedding server running a local model like bge-base-en-v1.5.
Key Takeaways
- Separate the indexing pipeline from the query API — they have different scaling requirements and failure modes
- Cache common queries in Redis with a 1-hour TTL — 20–40% of production queries are near-duplicates
- Never re-index on API startup — load the persisted vector store (under 1 second), never rebuild it
- Use incremental indexing with file content hashing — only re-index documents that have actually changed
- Set explicit LLM timeouts (30s) and build graceful fallbacks — LLM APIs go down, your service should not
- Emit structured logs for every query: request ID, retrieval latency, LLM latency, chunk count, sources, cache status
- Use a persistent volume or managed vector database — never store the index on ephemeral Docker disk
- Implement cache invalidation when documents change — stale cached answers are worse than no cache
- Validate the vector store is non-empty on startup and alert if chunk count drops unexpectedly