Hybrid Search RAG: Fix the Exact Matches Vectors Miss (2026)
Hybrid Search in RAG Systems
There is a class of query that pure vector search handles badly. A user asks about "CVE-2024-21413" — a specific vulnerability identifier. The embedding model has never seen that exact string; it embeds it as something approximately related to security vulnerabilities in general. The top-5 results come back as chunks about vulnerability scanning, patch management, and CVSS scores — all semantically close, none of them the actual CVE description the user needed.
This is the failure mode of semantic-only retrieval: it finds things that mean the same thing, but fails on exact terms, product names, error codes, API method names, and identifiers. For general-purpose chat applications, this is acceptable. For technical documentation, legal search, or medical records, it's a showstopper.
Hybrid search combines dense vector retrieval (semantic similarity) with sparse keyword retrieval (exact term matching). The result is a retriever that handles both "what does the return policy say about digital products" and "CVE-2024-21413" correctly. This guide covers the theory, the implementation, and the tuning decisions that determine whether hybrid search actually improves your RAG system.
See the RAG Architecture Guide for the broader context of where retrieval fits in the RAG pipeline.
Concept Overview
Dense retrieval uses embedding vectors to find semantically similar documents. A query about "how to handle authentication errors" retrieves chunks about "dealing with login failures" and "403 response handling" even without those exact words in the query.
Sparse retrieval uses traditional inverted index search (BM25 being the standard algorithm) to find documents with exact or close term matches. The same query retrieves chunks that literally contain the words "authentication" and "errors."
Hybrid search scores documents using both methods and combines the scores. Done correctly, it captures both semantic intent and lexical precision. In practice, most production search systems that power RAG pipelines use hybrid retrieval — Elastic's default, Weaviate's recommended setting, and what Pinecone calls "hybrid search" in their managed service.
How It Works
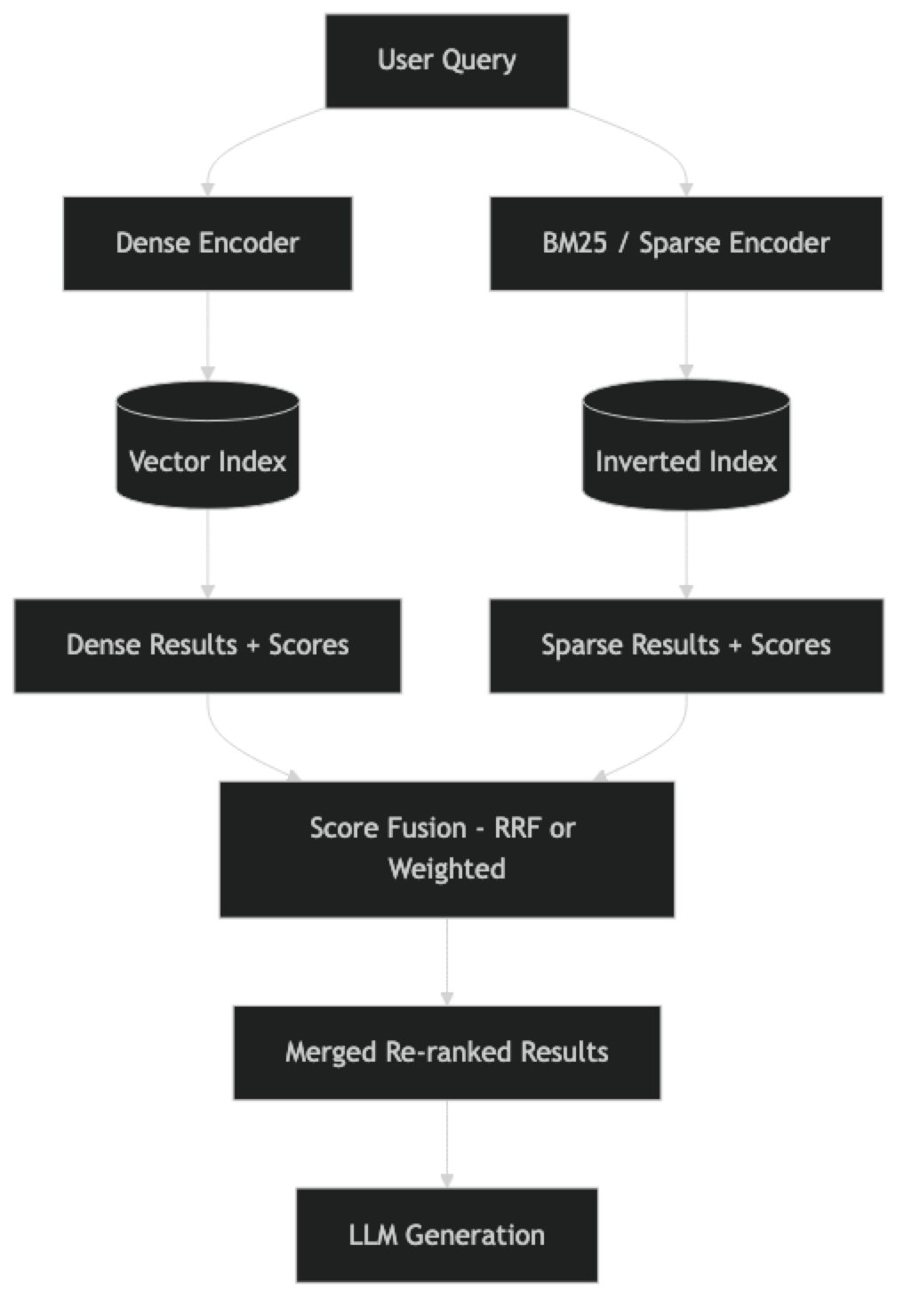
Score Fusion Methods
There are two common approaches to combining dense and sparse scores:
Reciprocal Rank Fusion (RRF): Combines results by rank position rather than raw score. Document ranked 1st in dense search and 5th in sparse search gets a combined score based on those ranks. RRF is robust to score scale differences between dense and sparse systems and requires no tuning.
RRF_score(d) = 1/(k + rank_dense(d)) + 1/(k + rank_sparse(d))Where k is typically 60 (a smoothing constant). Documents not retrieved by one method get rank = infinity.
Weighted sum: Directly combines normalized scores. Requires careful normalization since vector similarity scores (0–1 range) and BM25 scores (unbounded) are on different scales. The weight alpha controls the balance:
hybrid_score = alpha * dense_score + (1 - alpha) * sparse_scoreRRF is simpler to implement and performs comparably in most benchmarks. Use weighted sum only when you have validation data to tune alpha.
Implementation Example
Option 1: LangChain + Chroma + BM25 Retriever
# pip install langchain langchain-openai langchain-community chromadb rank-bm25
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_chroma import Chroma
from langchain_community.retrievers import BM25Retriever
from langchain.retrievers import EnsembleRetriever
# ── Load and chunk documents ──────────────────────────────────────────
loader = DirectoryLoader("./docs", glob="**/*.pdf", loader_cls=PyPDFLoader)
documents = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=64)
chunks = splitter.split_documents(documents)
print(f"Loaded {len(chunks)} chunks")
# ── Dense retriever (vector search) ──────────────────────────────────
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db",
collection_name="hybrid_docs"
)
dense_retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 10} # retrieve more candidates before fusion
)
# ── Sparse retriever (BM25 keyword search) ────────────────────────────
# BM25Retriever operates in-memory over the same chunks
bm25_retriever = BM25Retriever.from_documents(chunks)
bm25_retriever.k = 10 # same candidate count as dense
# ── Hybrid retriever (RRF fusion) ─────────────────────────────────────
# EnsembleRetriever implements Reciprocal Rank Fusion
hybrid_retriever = EnsembleRetriever(
retrievers=[dense_retriever, bm25_retriever],
weights=[0.6, 0.4] # weight dense slightly higher for general queries
# weights are used for score combination, not RRF rank fusion
# EnsembleRetriever uses RRF by default; weights affect tie-breaking
)
# ── QA Chain (LCEL) ───────────────────────────────────────────────────
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
prompt = ChatPromptTemplate.from_messages([
("system", """Answer based ONLY on the context below.
If the context does not contain the answer, say "I do not have that information."
Context:
{context}"""),
("human", "{question}"),
])
def format_docs(docs):
return "\n\n---\n\n".join(d.page_content for d in docs)
chain = (
{"context": hybrid_retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# ── Test queries ────────────────────────────────────────────────────────
test_queries = [
"CVE-2024-21413", # exact identifier — BM25 wins
"how to handle authentication failures", # semantic — dense wins
"API rate limit 429 error", # mixed — hybrid wins
"what is the refund policy", # natural language — dense wins
]
for query in test_queries:
answer = chain.invoke(query)
print(f"\nQ: {query}")
print(f"A: {answer[:200]}")Option 2: Weaviate Hybrid Search
Weaviate has native hybrid search that combines its vector index with BM25 internally:
# pip install weaviate-client langchain-weaviate
import weaviate
from weaviate.classes.query import HybridFusion
from langchain_weaviate import WeaviateVectorStore
from langchain_openai import OpenAIEmbeddings
# Connect to local Weaviate instance
client = weaviate.connect_to_local()
# Create collection with hybrid-capable schema
if not client.collections.exists("Documents"):
client.collections.create(
name="Documents",
vectorizer_config=weaviate.classes.config.Configure.Vectorizer.none(),
)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = WeaviateVectorStore(
client=client,
index_name="Documents",
text_key="text",
embedding=embeddings
)
# Hybrid search with alpha parameter
# alpha=1.0 → pure vector, alpha=0.0 → pure BM25
hybrid_retriever = vectorstore.as_retriever(
search_type="hybrid",
search_kwargs={
"k": 5,
"alpha": 0.75, # lean toward semantic
"fusion_type": HybridFusion.RELATIVE_SCORE # or RANKED
}
)Option 3: Pinecone Hybrid Search
Pinecone's managed service supports hybrid search natively with sparse-dense indexes:
# pip install pinecone-client pinecone-text
from pinecone import Pinecone
from pinecone_text.sparse import BM25Encoder
from langchain_openai import OpenAIEmbeddings
import numpy as np
pc = Pinecone(api_key="YOUR_PINECONE_API_KEY")
# Create a pod-based index with dotproduct metric (required for hybrid)
index = pc.Index("hybrid-index")
# Encode queries for hybrid search
bm25 = BM25Encoder().default() # pretrained BM25 on MS MARCO
def hybrid_search(query: str, top_k: int = 5, alpha: float = 0.7) -> list:
"""
Hybrid search combining dense (OpenAI) and sparse (BM25) vectors.
alpha: weight for dense component (0.0 = all sparse, 1.0 = all dense)
"""
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
dense_vector = embeddings.embed_query(query)
sparse_vector = bm25.encode_queries(query)
# Scale vectors by alpha
scaled_dense = [v * alpha for v in dense_vector]
scaled_sparse = {
"indices": sparse_vector["indices"],
"values": [v * (1 - alpha) for v in sparse_vector["values"]]
}
results = index.query(
vector=scaled_dense,
sparse_vector=scaled_sparse,
top_k=top_k,
include_metadata=True
)
return results["matches"]
# Test
matches = hybrid_search("authentication error 401", alpha=0.7)
for match in matches:
print(f"Score: {match['score']:.4f} | {match['metadata'].get('text', '')[:100]}")Best Practices
Use k=10 candidates from each retriever before fusion. Hybrid fusion needs more candidates per side to work effectively. If you use k=5 for both dense and sparse and then fuse to 5 final results, you're working with a small candidate pool. Retrieve 10 from each, fuse, and return the top 5.
Weight dense higher for natural language queries. For typical conversational RAG applications, weights=[0.6, 0.4] (dense:sparse) is a reasonable default. Increase the sparse weight for technical documentation with lots of exact identifiers, error codes, or product names.
Evaluate on your actual query distribution. The right alpha or weight depends heavily on query type. Measure precision@5 on a validation set of real queries before tuning.
Persist the BM25 index separately from the vector index. LangChain's BM25Retriever is in-memory. On application restart, you must rebuild it from the same chunks used to build the vector store. Serialize it with pickle or use a search engine like Elasticsearch that persists both.
Keep sparse and dense indexes in sync. When a document is added or deleted, update both indexes. Out-of-sync indexes produce inconsistent retrieval.
Common Mistakes
Using BM25 with raw, unprocessed text. BM25 performance degrades significantly on noisy text (HTML artifacts, repeated headers, garbled OCR output). Clean your documents before indexing or BM25 will surface irrelevant chunks based on repeated boilerplate tokens.
Expecting hybrid to always outperform pure semantic. For general conversational queries against well-written documents, semantic-only retrieval often matches or exceeds hybrid. Hybrid search earns its complexity on technical documentation with exact-match requirements.
Not deduplicating results. When the same chunk appears in both dense and sparse results, it may be counted twice in naive fusion implementations. Ensure deduplication by chunk ID before returning the final set.
Skipping stopword filtering in BM25. BM25 without stopword filtering gives high scores to chunks containing common words ("the", "is", "a") that appear in the query. Use NLTK or a simple stopword list when building the BM25 index.
Frequently Asked Questions
Does hybrid search always improve RAG quality? Not always. For general-purpose document Q&A with natural language queries, pure semantic retrieval often matches hybrid performance. Hybrid search provides the most improvement when queries contain specific terms, identifiers, error codes, or acronyms that do not appear in semantically similar chunks.
What is the difference between BM25 and TF-IDF? Both are bag-of-words models. BM25 improves on TF-IDF with term frequency saturation (diminishing returns on repeated term counts) and document length normalization. BM25 consistently outperforms TF-IDF in modern retrieval benchmarks and is the industry default for sparse retrieval.
Can I use hybrid search with local embeddings?
Yes. The dense component can use any embedding model — sentence-transformers, Ollama embeddings, or any HuggingFace model. The BM25 component is independent of the embedding model entirely. For fully offline hybrid search, combine BAAI/bge-small-en-v1.5 with BM25Retriever.
What is Reciprocal Rank Fusion versus weighted sum? RRF combines document ranks rather than raw scores, making it robust to score scale differences between dense and sparse systems. Weighted sum requires normalized scores and a tuned alpha parameter. Start with RRF — it performs comparably to tuned weighted sum in most benchmarks and requires no hyperparameter search.
How do I handle queries that are purely semantic versus purely lexical? The same hybrid retriever handles both well. When a query has no exact-match terms, BM25 returns low-confidence results that get downranked in fusion. When a query is all exact terms, the semantic results supplement BM25 with related context. No query routing needed.
How should I set the k value for each retriever in the ensemble?
Use k=10 candidates from each retriever before fusion, then return the top 5 final results. A small candidate pool (k=3 from each) limits fusion effectiveness — you need enough overlap and divergence between the two ranked lists for fusion to add value.
How do I benchmark whether hybrid actually improves over pure semantic for my use case? Build a test set of 30–50 queries with labeled relevant documents. Measure precision@5 for pure semantic, pure BM25, and hybrid. If the improvement is less than 5%, the added complexity of maintaining a BM25 index may not be worth it for your specific document type.
Key Takeaways
- Hybrid search combines dense vector retrieval (semantic similarity) with BM25 sparse retrieval (exact term matching) — solving the failure mode where pure semantic search misses identifiers, product names, and error codes
- Use
EnsembleRetrieverwithBM25RetrieverandChromafor a quick local hybrid setup; Weaviate and Pinecone offer managed native hybrid search for production - Reciprocal Rank Fusion (RRF) is the default fusion method — it requires no tuning and is robust to score scale differences
- Use k=10 candidates from each retriever before fusion to give the fusion algorithm enough signal
- Weight dense higher (0.6/0.4) for general prose; increase sparse weight for technical docs with lots of exact identifiers
- Hybrid search adds minimal latency — BM25 lookup is near-instant, so the cost is only the added vector candidates
- Always clean documents before building the BM25 index — boilerplate and noise produce false positives in keyword matching
- Benchmark on your actual query distribution before adopting hybrid; it is not universally better than semantic-only
What to Learn Next
- Full RAG pipeline → LangChain RAG Tutorial
- RAG architecture deep dive → RAG Architecture Guide
- Chunking for better retrieval → Document Chunking Strategies
- Vector search vs keyword search → Vector vs Keyword Search