Vector vs Relational DB: Pick Wrong and Rebuild Later (2026)
A team building an e-commerce product search asked: "Should we replace PostgreSQL with a vector database?" The answer was no — but for reasons that most blog posts do not explain well.
Their catalog, orders, inventory, and pricing all belonged in PostgreSQL. The product search experience — fuzzy, semantic, "show me items similar to this" — belonged in a vector database. The right architecture was both databases working together, not a replacement.
The "vector DB vs. relational DB" framing is almost always wrong. They solve different problems. Understanding the architectural boundary between them — where one ends and the other begins — is the practical skill that matters.
Concept Overview
Relational databases (PostgreSQL, MySQL, SQLite) are optimized for one query pattern: find rows where column X equals value Y, with precise set membership, range, and join semantics. Every query answers an exact question. The query planner knows how to use B-tree indexes to find matches in O(log n). Transactions ensure that concurrent operations do not corrupt data. This model has powered most software for 50 years and remains the right tool for structured, transactional data.
Vector databases are optimized for a different query pattern: find the K items most similar to this input, where similarity is defined geometrically in high-dimensional space. There is no "equal to" — there is only "near enough." Approximate nearest neighbor algorithms make this fast. Metadata filtering adds the ability to constrain results by structured attributes.
The key architectural difference is in what each system considers a "match." Relational databases require exact predicate satisfaction. Vector databases require geometric proximity within a tunable recall budget.
A common mistake in production is using a vector database to store data that should live in a relational database, and querying it with exact-match filters disguised as metadata predicates. If 95% of your queries are WHERE category = 'electronics' AND price < 500, you want a relational database with an index on those columns — not a vector database.
How It Works
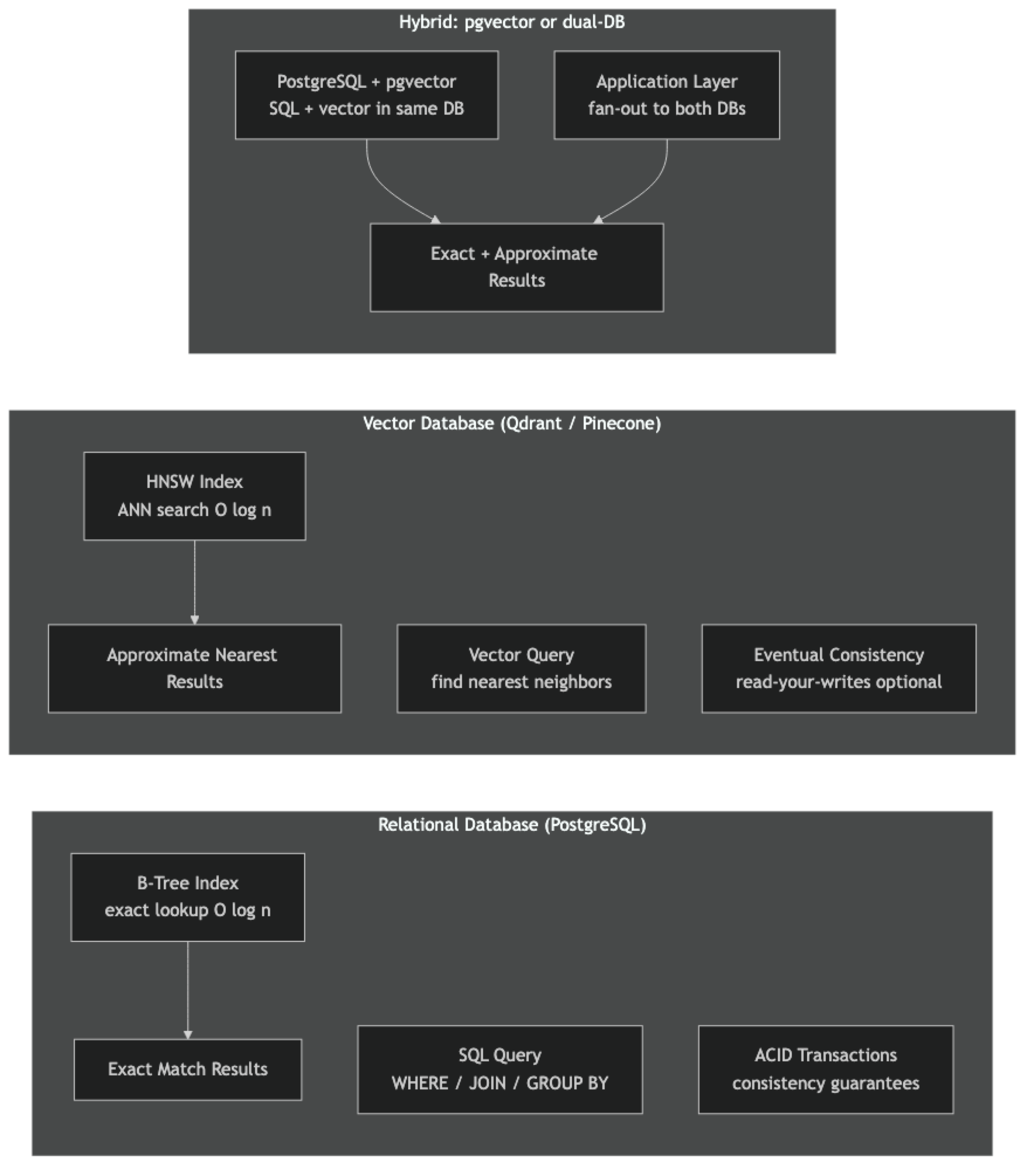
Relational databases use B-tree indexes for range and equality queries, full-text search with inverted indexes (PostgreSQL tsvector), and query planners that combine multiple indexes. Their data model is rows and columns with enforced schemas and foreign key relationships.
Vector databases store dense float vectors alongside payload metadata. Their primary index structure is HNSW or IVF for approximate nearest neighbor search. They support structured metadata filtering, but these filters are applied at the vector search layer — not via a general-purpose query planner. There are no joins, no foreign keys, no transactions.
Implementation Example
When PostgreSQL Is the Right Answer — Exact Structured Queries
pip install psycopg2-binaryimport psycopg2
conn = psycopg2.connect("postgresql://localhost/ecommerce")
cur = conn.cursor()
# These queries belong in PostgreSQL — they are exact and structured
# Vector databases cannot do this efficiently
# Order history for a user
cur.execute("""
SELECT o.id, o.total, o.status, p.name, oi.quantity
FROM orders o
JOIN order_items oi ON oi.order_id = o.id
JOIN products p ON p.id = oi.product_id
WHERE o.user_id = %s
AND o.created_at > NOW() - INTERVAL '30 days'
ORDER BY o.created_at DESC
""", (user_id,))
# Inventory aggregation by category
cur.execute("""
SELECT category, COUNT(*) as product_count, SUM(stock) as total_stock
FROM products
WHERE active = true
GROUP BY category
HAVING SUM(stock) < 100
ORDER BY total_stock ASC
""")
# These are exact joins with arithmetic — native relational operationsWhen a Vector Database Is the Right Answer — Semantic Search
import chromadb
from chromadb.utils import embedding_functions
client = chromadb.PersistentClient(path="./product_vectors")
ef = embedding_functions.SentenceTransformerEmbeddingFunction("BAAI/bge-base-en-v1.5")
collection = client.get_or_create_collection("products", embedding_function=ef)
# These queries belong in a vector database — they require semantic matching
# "I want something comfortable for working from home"
# No SQL WHERE clause can answer this without exact keyword matches
results = collection.query(
query_texts=["comfortable home office chair with lumbar support"],
n_results=10,
where={"in_stock": True}, # structured filter within vector search
)
# "Show me items similar to this product"
# Structured DB can only show items with the same category/tags
# Vector DB finds semantically similar items regardless of taxonomy
similar = collection.query(
query_embeddings=collection.get(ids=["prod_123"], include=["embeddings"])["embeddings"],
n_results=5,
)Hybrid Architecture — Both Databases Working Together
pip install psycopg2-binary pgvector chromadb sentence-transformersimport psycopg2
import chromadb
from chromadb.utils import embedding_functions
from psycopg2.extras import RealDictCursor
# Two databases, different roles
pg_conn = psycopg2.connect("postgresql://localhost/ecommerce")
vector_db = chromadb.PersistentClient(path="./product_search")
ef = embedding_functions.SentenceTransformerEmbeddingFunction("BAAI/bge-base-en-v1.5")
collection = vector_db.get_or_create_collection("products", embedding_function=ef)
def hybrid_product_search(
query: str,
max_price: float | None = None,
category: str | None = None,
min_stock: int = 1,
top_k: int = 10,
) -> list[dict]:
"""
Phase 1: Vector search to find semantically relevant products.
Phase 2: Fetch authoritative structured data from PostgreSQL.
Phase 3: Apply business filters that require relational joins.
"""
# --- Phase 1: Semantic retrieval ---
vector_filter = {}
if category:
vector_filter["category"] = category
vector_results = collection.query(
query_texts=[query],
n_results=top_k * 3, # over-fetch to account for filtering
where=vector_filter or None,
)
candidate_ids = vector_results["ids"][0]
score_map = {
id_: 1 - dist
for id_, dist in zip(candidate_ids, vector_results["distances"][0])
}
if not candidate_ids:
return []
# --- Phase 2: Authoritative data from PostgreSQL ---
cur = pg_conn.cursor(cursor_factory=RealDictCursor)
placeholders = ", ".join(["%s"] * len(candidate_ids))
cur.execute(f"""
SELECT
p.id, p.name, p.description, p.price, p.stock, p.category,
AVG(r.rating) as avg_rating, COUNT(r.id) as review_count
FROM products p
LEFT JOIN reviews r ON r.product_id = p.id
WHERE p.id IN ({placeholders})
AND p.stock >= %s
AND p.active = true
GROUP BY p.id
""", (*candidate_ids, min_stock))
rows = {row["id"]: dict(row) for row in cur.fetchall()}
# --- Phase 3: Combine and apply remaining filters ---
results = []
for product_id in candidate_ids:
if product_id not in rows:
continue # filtered out by SQL (out of stock, inactive, etc.)
row = rows[product_id]
if max_price and row["price"] > max_price:
continue
results.append({
**row,
"semantic_score": score_map[product_id],
"final_score": score_map[product_id] * 0.7 + (row["avg_rating"] or 3.0) / 5 * 0.3,
})
# Sort by blended score
results.sort(key=lambda r: r["final_score"], reverse=True)
return results[:top_k]
results = hybrid_product_search(
query="comfortable office chair for long work sessions",
max_price=500,
category="furniture",
top_k=5,
)
for r in results:
print(f"[{r['final_score']:.2f}] {r['name']} (${r['price']:.0f})")pgvector — Both in One Database
For teams that cannot operate two separate databases, pgvector adds vector search directly to PostgreSQL:
pip install psycopg2-binary pgvectorimport psycopg2
from pgvector.psycopg2 import register_vector
from sentence_transformers import SentenceTransformer
import numpy as np
conn = psycopg2.connect("postgresql://localhost/ecommerce")
register_vector(conn)
cur = conn.cursor()
# Setup
cur.execute("CREATE EXTENSION IF NOT EXISTS vector")
cur.execute("""
CREATE TABLE IF NOT EXISTS products (
id TEXT PRIMARY KEY,
name TEXT NOT NULL,
price NUMERIC,
stock INT,
category TEXT,
active BOOLEAN DEFAULT true,
embedding vector(768)
)
""")
cur.execute("""
CREATE INDEX IF NOT EXISTS products_embedding_idx
ON products USING hnsw (embedding vector_cosine_ops)
WITH (m = 32, ef_construction = 200)
""")
conn.commit()
model = SentenceTransformer("BAAI/bge-base-en-v1.5")
def embed(text: str) -> list[float]:
vec = model.encode([text], normalize_embeddings=True)[0]
return vec.tolist()
# Insert product with embedding
cur.execute("""
INSERT INTO products (id, name, price, stock, category, embedding)
VALUES (%s, %s, %s, %s, %s, %s)
ON CONFLICT (id) DO UPDATE SET
name = EXCLUDED.name, embedding = EXCLUDED.embedding
""", ("p001", "Ergonomic Office Chair with Lumbar Support", 349.99, 45, "furniture",
embed("Ergonomic office chair lumbar support armrests adjustable height")))
conn.commit()
# Semantic search + SQL predicates in one query
query_vec = embed("comfortable chair for work from home")
cur.execute("""
SELECT
id, name, price, stock,
1 - (embedding <=> %s) AS similarity,
(SELECT AVG(rating) FROM reviews WHERE product_id = products.id) AS avg_rating
FROM products
WHERE active = true
AND stock > 0
AND price < 600
AND category = 'furniture'
ORDER BY embedding <=> %s
LIMIT 5
""", (query_vec, query_vec))
for row in cur.fetchall():
print(f"[{row[4]:.3f}] {row[1]} (${row[2]:.0f}) - rating: {row[5] or 'N/A'}")Best Practices
Let each database do what it is designed for. Relational DB for: user accounts, orders, inventory, pricing, join-heavy analytics. Vector DB for: semantic search, similarity-based recommendations, RAG document retrieval. Hybrid: vector search returns candidate IDs, relational DB fetches authoritative data by ID.
Use pgvector when operational simplicity matters more than maximum scale. Running one PostgreSQL database instead of PostgreSQL + Pinecone is a significant reduction in operational complexity. For datasets under 5M vectors and query volumes under 1000 QPS, pgvector is often the correct engineering choice.
Cache vector search results aggressively. Vector search results for the same query are deterministic for the same index state. Cache results in Redis for 10–60 minutes. Serve cached results while the index updates in the background.
Do not replicate structured data into vector database metadata. Store only the fields you need for filtering in vector database metadata. Fetch authoritative structured data (price, inventory, user data) from the relational database by ID after vector retrieval. This keeps your vector database schema simple and avoids synchronization bugs.
Common Mistakes
Trying to do SQL-style joins in a vector database. Vector databases do not support joins. If you find yourself writing application-level join logic across multiple vector collections, that data probably belongs in a relational database.
Storing mutable business data in vector database metadata. Price, inventory, and availability change frequently. If you store these in vector database metadata, you need a synchronization process to keep them current. It is simpler to store only stable content-based attributes in the vector DB and fetch volatile data from your relational DB by ID.
Using vector similarity as a substitute for exact filtering. Searching for "products with exactly this SKU" or "orders from exactly this date" with vector similarity is wrong — these are exact queries that belong in a relational database with B-tree indexes. Vector similarity is for fuzzy, semantic matching.
Choosing a vector database because it is trendy, not because you have a similarity search problem. If your search is primarily keyword-based (part numbers, SKUs, exact names), PostgreSQL full-text search with tsvector is simpler, faster, and more precise. Add vector search only when you have a semantic matching problem that keywords cannot solve.
Key Takeaways
- Relational databases and vector databases are complementary — they solve fundamentally different query problems and should coexist, not replace each other
- Relational databases handle exact predicates, joins, transactions, and structured aggregations; vector databases handle semantic similarity and approximate nearest neighbor search
- The correct hybrid architecture: vector database for semantic candidate retrieval, relational database for authoritative structured data fetched by ID
- pgvector collapses both concerns into a single PostgreSQL database and is the right choice for datasets under 5 million vectors
- Do not store mutable business data (price, inventory) in vector database metadata — it creates synchronization debt that compounds
- If 95% of your queries are exact WHERE clauses, you do not have a semantic search problem and should not reach for a vector database
- Vector databases have no ACID transactions, no foreign keys, and no joins — they are not substitutes for relational databases
- Cache vector search results in Redis to reduce redundant ANN searches for repeated queries
FAQ
Can I replace my relational database entirely with a vector database? No, and you should not try. Vector databases have no transactions, no foreign keys, no joins, and approximate (not exact) search. For any application with user accounts, orders, payments, or complex relational data, a relational database is non-negotiable. Vector databases augment — they do not replace.
Is pgvector production-ready? Yes, as of PostgreSQL 16+ with pgvector 0.6+, HNSW indexing in pgvector is production-grade. Companies like Supabase, Neon, and many startups run pgvector in production at meaningful scale. The limitation is single-node capacity — above 10–20M vectors, you need a dedicated vector database or distribution strategy.
How do I decide between pgvector and a dedicated vector database? Use pgvector if: you are already on PostgreSQL, your vector dataset is under 5M vectors, and operational simplicity matters. Use a dedicated vector database (Qdrant, Pinecone, Weaviate) if: you need more than 10M vectors, you need sub-5ms query latency at high concurrency, or you need features like multi-vector queries, named vectors, or built-in hybrid search.
Does PostgreSQL full-text search replace vector search for document retrieval?
For keyword-based retrieval, yes — tsvector + tsquery with GIN indexes is efficient and precise. For semantic retrieval (finding documents by meaning, not keywords), no — full-text search cannot bridge vocabulary mismatches. For most production document search systems, combining BM25 (PostgreSQL full-text) with vector search via pgvector gives the best results.
How do I keep vector database metadata in sync with my relational database? Two approaches: event-driven sync (update vector metadata on every relational change via triggers or CDC) or on-demand fetch (store only stable identifiers in vector metadata and fetch current values from the relational DB by ID at query time). The second approach is simpler and avoids stale metadata bugs.
What query patterns indicate I should use a vector database? Use a vector database when: users describe what they want in natural language, you want to find items similar to a given item, you are building RAG retrieval, or you need to cluster or deduplicate content at scale. Do not use a vector database for exact lookups by primary key, range queries on structured fields, or complex aggregations.
Can vector search and full-text search be combined in PostgreSQL?
Yes. pgvector adds vector similarity alongside PostgreSQL's built-in full-text search (tsvector). You can write a single SQL query that uses both <=> (cosine distance) and @@ (full-text match) with a weighted combination. This is a fully functional hybrid search implementation without any additional infrastructure.