Vector Recommendations: Build Personalized AI Recs (2026)
Netflix's "More Like This" feature does not run a rules engine. Spotify's "Discover Weekly" does not use a hand-crafted tag matching system. Both are vector nearest-neighbor lookups at their core — find the items whose embeddings are closest to the items the user has engaged with.
The shift from collaborative filtering matrices to vector-based recommendations happened because dense embeddings handle the fundamental challenge collaborative filtering cannot: cold start. A new item with no interaction history still gets a meaningful embedding from its content. A new user still gets a reasonable starting vector from their first few clicks.
Vector search turns recommendation from a matrix factorization problem into a geometry problem. And geometry at scale is exactly what vector databases are built to solve.
Concept Overview
Vector-based recommendation systems represent both users and items as points in the same embedding space. Items close to a user's vector are good recommendations. Items close to an item the user just engaged with are similar-item recommendations.
There are two main approaches to generating these embeddings:
Content-based embeddings — embed item metadata (description, tags, attributes) using a text embedding model. Fast to implement, handles cold start well, limited to surface-level similarity.
Collaborative filtering embeddings — train a model on user-item interaction data (clicks, purchases, ratings) to produce embeddings that capture behavioral patterns. More powerful for personalization, requires substantial interaction history.
Two-tower models — a neural architecture that trains user and item encoders jointly on interaction data. The user tower encodes user features + history; the item tower encodes item features. Both output vectors in the same space. At query time, retrieve the user's current vector and find nearest item vectors via ANN.
In practice, production recommendation systems combine multiple signals: content embeddings for cold-start, collaborative embeddings for personalization, and re-ranking for business rules (margin, diversity, freshness).
How It Works
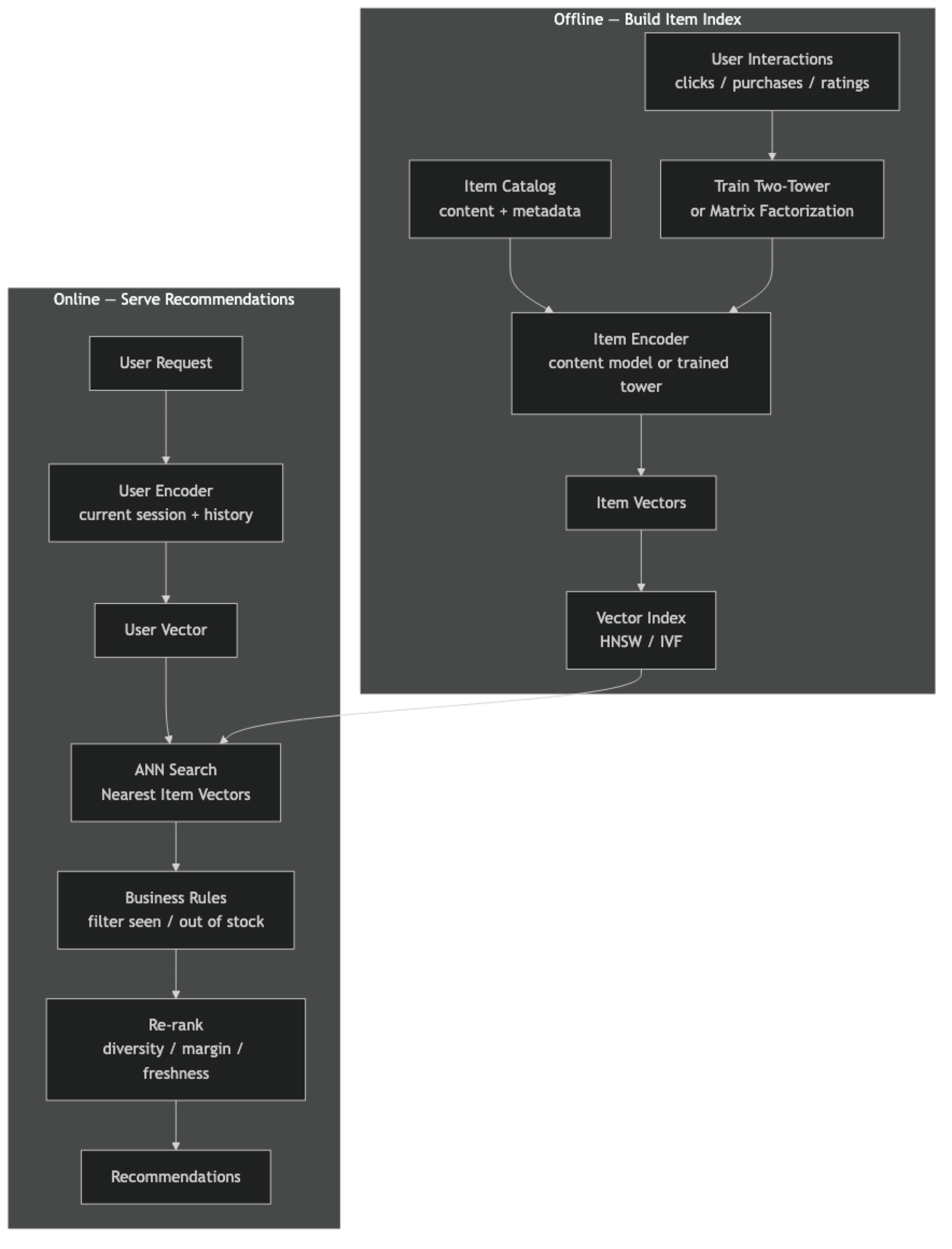
The key architectural insight is the separation between offline embedding generation and online ANN retrieval. Embedding items is expensive (model inference) but the results are stable — item content does not change often. This computation happens offline in batch. At query time, only the user vector computation and ANN search happen — both are fast.
Implementation Example
Content-Based Item Recommendations with ChromaDB
pip install chromadb sentence-transformersimport chromadb
from chromadb.utils import embedding_functions
from dataclasses import dataclass
@dataclass
class Item:
id: str
title: str
description: str
category: str
tags: list[str]
def to_text(self) -> str:
"""Rich text representation for embedding — more context = better similarity."""
return (
f"{self.title}. "
f"Category: {self.category}. "
f"Tags: {', '.join(self.tags)}. "
f"{self.description}"
)
client = chromadb.PersistentClient(path="./rec_db")
ef = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="BAAI/bge-base-en-v1.5"
)
item_collection = client.get_or_create_collection(
name="items",
embedding_function=ef,
metadata={"hnsw:space": "cosine", "hnsw:M": 32},
)
# Catalog
items = [
Item("p001", "Python Machine Learning Cookbook", "500 recipes for ML with scikit-learn and PyTorch", "books", ["python", "ml", "pytorch", "recipes"]),
Item("p002", "Deep Learning with PyTorch", "Hands-on guide to neural networks and deep learning", "books", ["pytorch", "deep-learning", "neural-networks"]),
Item("p003", "Designing Data-Intensive Applications", "Principles for building scalable distributed systems", "books", ["system-design", "databases", "distributed"]),
Item("p004", "The Pragmatic Programmer", "Career advice and best practices for software engineers", "books", ["career", "software-engineering", "best-practices"]),
Item("p005", "Vector Database Fundamentals Course", "Video course covering embedding models and ANN search", "courses", ["vector-db", "embeddings", "ml", "search"]),
Item("p006", "Building LLM Applications", "Workshop on RAG, agents, and LLM-powered products", "courses", ["llm", "rag", "agents", "openai"]),
Item("p007", "PostgreSQL Performance Tuning", "Advanced indexing and query optimization for PostgreSQL", "courses", ["postgresql", "databases", "performance"]),
Item("p008", "System Design Interview", "Comprehensive guide to distributed systems design interviews", "books", ["system-design", "interviews", "distributed"]),
]
# Index items
item_collection.upsert(
ids=[item.id for item in items],
documents=[item.to_text() for item in items],
metadatas=[{"title": item.title, "category": item.category, "tags": ",".join(item.tags)}
for item in items],
)
def similar_items(item_id: str, top_k: int = 3, same_category: bool = False) -> list[dict]:
"""Find items similar to a given item."""
item_data = item_collection.get(ids=[item_id], include=["documents"])
if not item_data["documents"]:
return []
item_text = item_data["documents"][0]
filter_clause = None
if same_category:
item_meta = item_collection.get(ids=[item_id], include=["metadatas"])["metadatas"][0]
filter_clause = {"category": item_meta["category"]}
results = item_collection.query(
query_texts=[item_text],
n_results=top_k + 1, # +1 because the item itself will appear
where=filter_clause,
)
# Exclude the query item itself
return [
{"id": id_, "title": meta["title"], "score": 1 - dist}
for id_, meta, dist in zip(
results["ids"][0], results["metadatas"][0], results["distances"][0]
)
if id_ != item_id
][:top_k]
# Similar items to "Deep Learning with PyTorch"
recs = similar_items("p002", top_k=3)
print("Similar to 'Deep Learning with PyTorch':")
for r in recs:
print(f" [{r['score']:.3f}] {r['title']}")User-Based Recommendations via Session History
def user_vector_from_history(
engaged_item_ids: list[str],
weights: list[float] | None = None,
) -> np.ndarray:
"""
Compute a user representation by averaging the embeddings of items
they engaged with, optionally weighted by recency or engagement strength.
"""
if not engaged_item_ids:
return None
item_data = item_collection.get(
ids=engaged_item_ids,
include=["embeddings"],
)
embeddings = np.array(item_data["embeddings"])
if weights:
w = np.array(weights, dtype=np.float32)
w /= w.sum()
user_vec = (embeddings * w[:, None]).sum(axis=0)
else:
user_vec = embeddings.mean(axis=0)
return user_vec / np.linalg.norm(user_vec) # normalize
def recommend_for_user(
user_history: list[str],
recency_weights: list[float] | None = None,
top_k: int = 5,
exclude_seen: bool = True,
) -> list[dict]:
user_vec = user_vector_from_history(user_history, recency_weights)
if user_vec is None:
return []
results = item_collection.query(
query_embeddings=[user_vec.tolist()],
n_results=top_k + len(user_history), # over-fetch to filter seen items
)
seen = set(user_history) if exclude_seen else set()
recs = []
for id_, meta, dist in zip(
results["ids"][0], results["metadatas"][0], results["distances"][0]
):
if id_ in seen:
continue
recs.append({"id": id_, "title": meta["title"], "score": 1 - dist})
if len(recs) >= top_k:
break
return recs
import numpy as np
# User who engaged with: Python ML book, Deep Learning book
# More recent item (p002) gets higher weight
user_history = ["p001", "p002"]
recency_weights = [0.3, 0.7] # recent items weighted more heavily
print("\nRecommendations for user (history: ML + DL books):")
for r in recommend_for_user(user_history, recency_weights, top_k=3):
print(f" [{r['score']:.3f}] {r['title']}")Two-Tower Model Training Sketch
pip install torch sentence-transformersimport torch
import torch.nn as nn
import numpy as np
from sentence_transformers import SentenceTransformer
class TwoTowerModel(nn.Module):
"""
Simplified two-tower recommendation model.
User tower: encodes user feature vector.
Item tower: encodes item text embedding.
Both project to a shared d-dimensional space.
"""
def __init__(self, user_feat_dim: int, item_embed_dim: int, shared_dim: int = 128):
super().__init__()
self.user_tower = nn.Sequential(
nn.Linear(user_feat_dim, 256),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(256, shared_dim),
)
self.item_tower = nn.Sequential(
nn.Linear(item_embed_dim, 256),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(256, shared_dim),
)
def encode_user(self, user_features: torch.Tensor) -> torch.Tensor:
out = self.user_tower(user_features)
return nn.functional.normalize(out, dim=-1)
def encode_item(self, item_embeddings: torch.Tensor) -> torch.Tensor:
out = self.item_tower(item_embeddings)
return nn.functional.normalize(out, dim=-1)
def forward(self, user_features, item_embeddings):
u = self.encode_user(user_features)
i = self.encode_item(item_embeddings)
return (u * i).sum(dim=-1) # dot product similarity
# Training with in-batch negatives (standard approach)
def train_step(model, optimizer, user_batch, pos_item_batch, neg_item_batch=None):
"""
user_batch: (B, user_feat_dim)
pos_item_batch: (B, item_embed_dim) — items the user interacted with
neg_item_batch: None — use other items in batch as negatives (in-batch negatives)
"""
u_vecs = model.encode_user(user_batch) # (B, shared_dim)
i_vecs = model.encode_item(pos_item_batch) # (B, shared_dim)
# In-batch negative loss: similarity matrix, diagonal = positive pairs
logits = u_vecs @ i_vecs.T # (B, B)
labels = torch.arange(len(u_vecs))
loss = nn.CrossEntropyLoss()(logits, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()
# Model instantiation
USER_FEAT_DIM = 64 # e.g., user age, location, platform, engagement stats
ITEM_EMBED_DIM = 768 # BGE-base output dimension
model = TwoTowerModel(USER_FEAT_DIM, ITEM_EMBED_DIM, shared_dim=128)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# After training: pre-compute item vectors and load into vector DB
# At inference: encode user vector -> ANN search in item indexBest Practices
Enrich item text before embedding. The embedding quality depends on the richness of the input text. Concatenating title + description + category + tags + brand gives a much richer semantic representation than title alone. Test the difference by measuring item similarity quality on a held-out set of known-similar items.
Weight user history by recency and engagement type. A purchase should count more than a browse; an item viewed 1 hour ago should count more than one viewed 30 days ago. Simple exponential decay on timestamps and linear scaling by engagement type (purchase=3x, cart=2x, click=1x) improves recommendation quality significantly.
Separate cold-start and warm-start recommendation paths. New users and new items need different treatment. Content-based embeddings handle cold start (no interaction history available). Switch to collaborative embeddings once a user has 10+ interactions. Keep both systems running in parallel and blend their outputs.
Periodically refresh user vectors, not item vectors. Item content changes rarely. User behavior changes daily. Update user vectors in near real-time (batch job every few hours, or stream-based updates). Item vectors can be rebuilt weekly or on content update events.
A/B test recommendation quality with business metrics, not just embedding similarity. Closer vectors do not always mean better business outcomes. A diverse set of recommendations (lower average similarity to each other) may drive higher total engagement than a tight cluster of very similar items.
Common Mistakes
Using raw text embeddings for items without domain adaptation. General text embedding models were trained on web text. "16GB DDR5 RAM module 5600MHz" and "memory upgrade for gaming PC" may be far apart in a general model's space but represent the same product intent. Evaluate embedding quality on your specific item catalog before assuming general models work.
Not filtering already-seen items. The items a user has already engaged with will appear as high-similarity results. Always exclude the user's interaction history from recommendation results. This is a silent bug that produces recommendations the user has already seen and rejected.
Ignoring popularity bias in collaborative embeddings. Items with many interactions dominate collaborative embedding spaces. Rare long-tail items cluster at the periphery and are rarely recommended. Add a popularity penalty or separate long-tail boosting to surface niche items to users with niche tastes.
Re-embedding all items whenever you update one. If you update item descriptions, only those items need re-embedding. Content-addressed caching (embed by content hash, not item ID) lets you skip re-embedding for unchanged items and only update what changed.
Not deduplicating near-identical items in results. ANN search on item embeddings may return 3 variants of the same product (different colors, sizes) as 3 separate top results. This wastes recommendation slots. Post-process results to collapse near-identical items (similarity > 0.95) into one representative result.
Key Takeaways
- Vector-based recommendation converts recommendation into a geometry problem: find item vectors nearest to the user's current vector in embedding space
- Content-based embeddings handle cold start (new items with no history); collaborative embeddings handle behavioral personalization (users with interaction history)
- Two-tower models train user and item encoders jointly so both output vectors in the same shared embedding space
- Weight user history by recency (exponential decay) and engagement type (purchase > cart > click) to produce a more accurate user vector
- Always exclude already-seen items from recommendation results — failure to do so is a silent bug that degrades user experience
- Enrich item text before embedding by concatenating title, description, category, and tags — richer context produces better semantic similarity
- Item vectors are stable (rebuild weekly); user vectors change constantly (update every few hours or via streaming)
- A/B test with business metrics (CTR, conversion, session length), not just embedding similarity — diverse recommendations often outperform tight clusters
FAQ
How is vector-based recommendation different from collaborative filtering? Traditional collaborative filtering (matrix factorization, ALS) produces user and item latent factors as output. Vector-based recommendation is the same idea but treated as a retrieval problem — the latent factors are embeddings, and nearest-neighbor search finds the top recommendations efficiently at scale. Modern two-tower models are collaborative filtering implemented with deep learning + ANN retrieval.
What is the "cold start problem" in recommendations? New items with no interaction history cannot be embedded using behavioral data — there are no interactions to learn from. Content-based embeddings solve this: embed the item's text/metadata immediately, making it recommendable before anyone has interacted with it. Collaborative embeddings are then blended in as interactions accumulate.
How many items can a vector recommendation system serve? With HNSW indexing, single-node systems handle 10–50M item vectors at sub-10ms latency. Distributed setups (multiple Qdrant or Pinecone nodes) serve hundreds of millions of items. Netflix and Spotify operate at the billion-item scale using custom distributed ANN infrastructure.
Should I use a separate embedding model for recommendation vs. search? Often yes. Search embeddings are trained for asymmetric query-document retrieval. Recommendation embeddings are trained on behavioral similarity (users who interacted with A also interacted with B). For content-based recommendations that need to align with search results (e.g., "items similar to your search"), using the same embedding model simplifies the system. For pure behavioral recommendation, specialized collaborative embedding models perform better.
How do I handle item catalog updates in a vector recommendation system? Use content-hash-addressed caching — embed by the hash of the item content, not the item ID. When an item is updated, only that item needs re-embedding. New items are embedded on creation and inserted into the index incrementally (HNSW handles this). Deleted items should be removed from the index to avoid recommending unavailable products.
What is in-batch negative training for two-tower models? In-batch negative training treats all other items in the current training batch as negative examples for each user-item pair. This is efficient because no separate negative sampling is needed — the batch itself provides negatives. The model learns to score the positive (interacted) item higher than all other items in the batch. Larger batch sizes provide harder negatives and generally improve model quality.
How do I measure the quality of a recommendation system? Use offline metrics: precision@K (fraction of recommendations the user actually engaged with), recall@K (fraction of items the user engaged with that appeared in recommendations), and NDCG (position-weighted ranking quality). Complement with online A/B test metrics: click-through rate, conversion rate, session length, and revenue per user. Offline metrics predict online performance imperfectly — always validate with an A/B test.