Synthetic Data: Generate Training Sets When Data Is Scarce (2026)
Synthetic Data for LLM Fine-Tuning: Generate Training Data with GPT-4o
Last updated: March 2026
Real training data is almost always scarce. For domain-specific fine-tuning, you might have hundreds of internal documents but very few well-formatted instruction-response pairs. Human annotation is expensive — $1–5 per high-quality example means a 10,000-example dataset costs tens of thousands of dollars. Teams that build excellent fine-tuned models often do it not with more human annotation, but with well-designed synthetic data pipelines.
The core insight is simple: if you have a capable model (GPT-4, Claude), you can use it to generate training data for a smaller, cheaper, specialized model. This is what Meta did with Llama-based instruction tuning, what Mistral's team did for various fine-tunes, and what most successful domain-specific fine-tuning projects do in practice.
The techniques have evolved significantly. Early approaches like the original Self-Instruct were straightforward prompting with minimal quality control. Modern pipelines use structured generation, multi-step quality filtering, deduplication, and evolution-based difficulty scaling. This guide covers the full pipeline.
Concept Overview
Self-Instruct (Wang et al., 2022) is the foundational technique. Start with a small set of seed examples (often just 175). Use a capable model to generate new instruction-response pairs using the seed examples as few-shot demonstrations. Filter the generated examples by quality and diversity. Add the filtered examples to the seed pool and repeat. The original Alpaca dataset was created this way using GPT-3.
Evol-Instruct (Xu et al., 2023) improves on Self-Instruct by "evolving" simple instructions into more complex ones. A capable model rewrites each seed instruction to be harder: by adding more constraints, requiring more reasoning steps, or making the context more specific. The WizardLM family of models used this technique to produce instruction data that outperformed raw Self-Instruct data on benchmarks.
Persona-based generation assigns different expert personas to the generating model for diversity. The same instruction generated by a "senior software engineer", a "Python educator", and a "technical writer" will produce stylistically different, complementary training examples — all from one seed instruction.
Quality criteria for synthetic data:
- Response length appropriate to the instruction complexity
- No sycophantic openers ("Sure! Of course! Great question!")
- No AI self-references ("As an AI language model...")
- Factually accurate (verifiable claims, no hallucinations)
- Instruction and response are actually aligned
How It Works
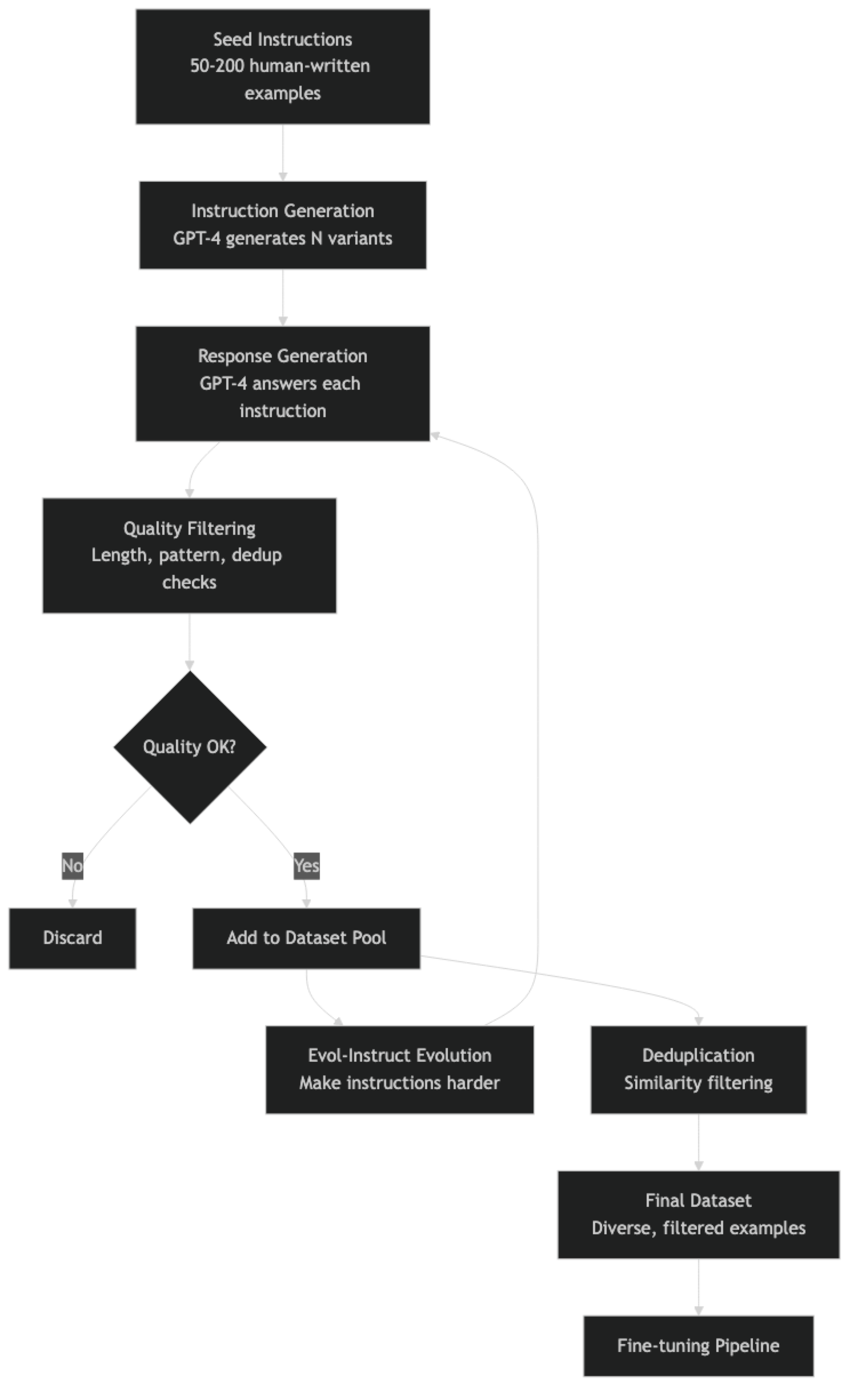
In practice, running 3–4 rounds of Self-Instruct evolution with quality filtering produces datasets that meaningfully improve fine-tuned model quality over first-round generation alone.
Implementation Example
Complete 1,000-Example Generation Pipeline
"""
synthetic_data_generator.py
Generates 1,000 synthetic training examples for LLM fine-tuning.
"""
import json
import time
import hashlib
import random
import re
from openai import OpenAI
from datasets import Dataset
from typing import Optional
client = OpenAI()
# ===== Configuration =====
DOMAIN = "Python backend development with FastAPI"
TARGET_EXAMPLES = 1000
MODEL = "gpt-4o" # Strong model for generation
TEMPERATURE = 0.8 # Higher temp = more diversity
OUTPUT_FILE = "synthetic_train.jsonl"
# ===== Seed Instructions =====
# Start with 20-50 human-written examples representing the task well
SEED_INSTRUCTIONS = [
"Explain how to implement dependency injection in FastAPI.",
"Write a FastAPI endpoint that handles file uploads with validation.",
"What is the difference between sync and async endpoints in FastAPI?",
"How do I implement JWT authentication middleware in FastAPI?",
"Explain background tasks in FastAPI and when to use them.",
"Write a FastAPI route that streams a response using StreamingResponse.",
"How do I structure a large FastAPI application with multiple routers?",
"Explain how to use Pydantic v2 for request validation in FastAPI.",
"Write a FastAPI endpoint with pagination using query parameters.",
"How do I add rate limiting to FastAPI endpoints?",
# Add 10-40 more seed instructions...
]
# ===== Instruction Generation =====
INSTRUCTION_GENERATION_PROMPT = """You are creating training data for a {domain} AI assistant.
Here are example instructions for this assistant:
{examples}
Generate {n} NEW, DISTINCT instructions that:
- Are practical and specific (not vague)
- Have clear, measurable answers
- Cover different aspects of {domain}
- Are not similar to the examples above
Format as a JSON array of strings:
["instruction 1", "instruction 2", ...]"""
def generate_instructions(n=5, existing_instructions=None):
"""Generate new instructions from seed examples."""
existing = existing_instructions or SEED_INSTRUCTIONS
# Sample 8 random examples as demonstrations
sample = random.sample(existing, min(8, len(existing)))
examples_str = "\n".join(f"- {ex}" for ex in sample)
prompt = INSTRUCTION_GENERATION_PROMPT.format(
domain=DOMAIN, examples=examples_str, n=n
)
try:
response = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": prompt}],
temperature=TEMPERATURE,
response_format={"type": "json_object"},
)
content = response.choices[0].message.content
# Extract array from JSON object
data = json.loads(content)
if isinstance(data, list):
return data
# Try to find a list value in the dict
for v in data.values():
if isinstance(v, list):
return v
return []
except Exception as e:
print(f"Instruction generation error: {e}")
return []
# ===== Response Generation =====
RESPONSE_GENERATION_PROMPT = """You are an expert {domain} engineer. A developer asks:
{instruction}
Write a detailed, technically accurate response. Requirements:
- Be specific and practical — include code examples where appropriate
- Be at least 150 words
- Do not start with "Sure!", "Of course!", "Great question!"
- Do not say "As an AI" or mention being an AI
- If writing code, make it runnable and properly formatted
- Focus on what a senior engineer would actually explain"""
def generate_response(instruction: str, persona: str = None) -> Optional[str]:
"""Generate a high-quality response to an instruction."""
domain_str = f"{persona} working with {DOMAIN}" if persona else DOMAIN
prompt = RESPONSE_GENERATION_PROMPT.format(
domain=domain_str, instruction=instruction
)
try:
response = client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": prompt}],
temperature=max(TEMPERATURE - 0.2, 0.3), # Slightly lower for accuracy
)
return response.choices[0].message.content
except Exception as e:
print(f"Response generation error: {e}")
return None
# ===== Evol-Instruct Evolution =====
EVOLUTION_PROMPT = """Rewrite this instruction to make it more complex and challenging:
Original: {instruction}
Make it harder by:
- Adding specific constraints or requirements
- Requiring more steps or deeper reasoning
- Making the context more specific or technical
- Adding edge cases to handle
Write ONLY the evolved instruction, nothing else."""
def evolve_instruction(instruction: str) -> Optional[str]:
"""Make an instruction more complex using Evol-Instruct."""
try:
response = client.chat.completions.create(
model=MODEL,
messages=[{
"role": "user",
"content": EVOLUTION_PROMPT.format(instruction=instruction)
}],
temperature=0.7,
)
evolved = response.choices[0].message.content.strip()
# Reject evolutions that are too similar or too long
if len(evolved) > 500 or evolved == instruction:
return None
return evolved
except Exception as e:
return None
# ===== Quality Filtering =====
BAD_PATTERNS = [
r"^Sure[!,]",
r"^Of course[!,]",
r"^Great question",
r"^Certainly[!,]",
r"As an AI (language model|assistant)",
r"I (don't|cannot|can't) (browse|access|connect to) the internet",
r"My knowledge cutoff",
]
def is_quality_response(response: str, instruction: str) -> bool:
"""Filter low-quality synthetic responses."""
if not response:
return False
# Length check
word_count = len(response.split())
if word_count < 50:
return False
if word_count > 1500:
return False
# Pattern checks
for pattern in BAD_PATTERNS:
if re.search(pattern, response, re.IGNORECASE):
return False
# Repetition check
sentences = response.split('.')
if len(sentences) > 5:
unique_sentences = set(s.strip().lower() for s in sentences if s.strip())
if len(unique_sentences) / len(sentences) < 0.6:
return False
# Instruction-response alignment (simple heuristic)
instruction_keywords = set(instruction.lower().split()[:10])
response_lower = response.lower()
keyword_hits = sum(1 for k in instruction_keywords if k in response_lower and len(k) > 4)
if keyword_hits < 1: # Response doesn't reference the instruction at all
return False
return True
def compute_hash(text: str) -> str:
normalized = " ".join(text.lower().split())
return hashlib.md5(normalized.encode()).hexdigest()
# ===== Main Generation Loop =====
def generate_dataset(target: int = 1000) -> list:
examples = []
seen_hashes = set()
instruction_pool = list(SEED_INSTRUCTIONS)
generation_round = 0
personas = [
"Senior Software Engineer",
"Python Tech Lead",
"Backend Developer",
"API Architect",
"DevOps Engineer",
]
print(f"Target: {target} examples")
print(f"Starting generation...")
while len(examples) < target:
generation_round += 1
print(f"\n--- Round {generation_round} | Current: {len(examples)}/{target} ---")
# Generate new instructions from current pool
new_instructions = generate_instructions(
n=10, existing_instructions=instruction_pool
)
print(f"Generated {len(new_instructions)} new instructions")
# Optionally evolve some instructions for diversity
evolved = []
for inst in random.sample(new_instructions, min(3, len(new_instructions))):
ev = evolve_instruction(inst)
if ev:
evolved.append(ev)
all_instructions = new_instructions + evolved
instruction_pool.extend(all_instructions)
# Trim pool to prevent it from getting too large
if len(instruction_pool) > 500:
instruction_pool = instruction_pool[-500:]
# Generate responses for each instruction
for instruction in all_instructions:
if len(examples) >= target:
break
# Dedup check on instruction
inst_hash = compute_hash(instruction)
if inst_hash in seen_hashes:
continue
seen_hashes.add(inst_hash)
# Generate with a random persona
persona = random.choice(personas)
response = generate_response(instruction, persona)
# Quality filter
if not is_quality_response(response, instruction):
continue
example = {
"messages": [
{"role": "system", "content": f"You are an expert {DOMAIN} engineer."},
{"role": "user", "content": instruction},
{"role": "assistant", "content": response},
]
}
examples.append(example)
if len(examples) % 50 == 0:
print(f"Progress: {len(examples)}/{target}")
# Save checkpoint
with open(OUTPUT_FILE, "w") as f:
for ex in examples:
f.write(json.dumps(ex) + "\n")
# Small delay to respect rate limits
time.sleep(1)
print(f"\nGeneration complete. {len(examples)} examples saved to {OUTPUT_FILE}")
return examples
# Run
if __name__ == "__main__":
dataset = generate_dataset(TARGET_EXAMPLES)
print(f"\nFinal dataset statistics:")
print(f" Total examples: {len(dataset)}")
response_lengths = [len(ex["messages"][-1]["content"].split()) for ex in dataset]
import statistics
print(f" Avg response length: {statistics.mean(response_lengths):.0f} words")
print(f" Median response length: {statistics.median(response_lengths):.0f} words")
print(f" Min: {min(response_lengths)}, Max: {max(response_lengths)}")Post-Generation Quality Verification
import random
def audit_dataset(filepath: str, sample_size: int = 20):
"""Sample and print examples for manual review."""
examples = []
with open(filepath) as f:
for line in f:
examples.append(json.loads(line))
sample = random.sample(examples, min(sample_size, len(examples)))
print(f"=== DATASET AUDIT — {len(examples)} examples ===\n")
for i, example in enumerate(sample):
messages = example["messages"]
instruction = next(m["content"] for m in messages if m["role"] == "user")
response = next(m["content"] for m in messages if m["role"] == "assistant")
print(f"--- Example {i+1} ---")
print(f"Instruction: {instruction[:100]}...")
print(f"Response ({len(response.split())} words): {response[:200]}...")
print()
# Run audit before using dataset for training
audit_dataset(OUTPUT_FILE)Best Practices
Use GPT-4o, not GPT-3.5, for data generation. The quality difference in generated training data is significant. Data generated by GPT-4o produces fine-tuned models that outperform those trained on GPT-3.5-generated data, even when training the same smaller model. The generation cost difference ($4 vs $0.50 for 1,000 examples) is negligible compared to training cost.
Generate more than you need, then filter. Target 1.5–2x your desired dataset size in raw generation, then filter down to your target. The filtering stage significantly improves final dataset quality and is much cheaper than regenerating examples.
Include code examples in technical domains. For code-adjacent tasks, responses with working code examples are more valuable than prose explanations. Structure your generation prompt to explicitly request code when appropriate. Verify code examples compile and run when possible.
Mix seed topic coverage deliberately. If your seed instructions are all about one topic, the generated instructions will cluster around it. Deliberately spread seed instructions across the relevant topic space to ensure coverage.
Common Mistakes
Not filtering for AI self-references. A model trained on data where the assistant says "As an AI, I cannot..." will reproduce that behavior at inference time. Filter all such patterns before training.
Using temperature 1.0 for technical response generation. High temperature is useful for diverse instruction generation. For response generation, it causes factual errors in technical content. Use 0.5–0.7 for response generation in technical domains.
Not auditing the dataset before training. Always manually review 50–100 examples before committing to a training run. Issues like topic drift, response quality degradation across rounds, or systematic formatting errors are only visible through manual inspection.
Generating only simple instructions. Easy, one-step instructions produce models that struggle with complex requests. Intentionally include harder instructions: multi-step tasks, edge cases, conflict resolution, and comparative analysis.
Ignoring licensing constraints on public seed data. If your seed examples come from public datasets, check their licenses. Some public datasets prohibit commercial use. When in doubt, write your own seed examples.
Summary
Synthetic data generation with GPT-4 or Claude makes it practical to create high-quality fine-tuning datasets without large annotation budgets. The core workflow — generate instructions from seeds, generate responses with quality personas, filter aggressively, evolve for complexity — produces datasets that rival human-annotated examples for task-specific fine-tuning.
The quality controls are the critical piece. Raw generation without filtering produces models that inherit bad generation patterns (sycophancy, AI self-references, hallucination). Structured filtering and manual auditing turn raw synthetic data into a reliable training signal.
Related Articles
- How to Build Fine-Tuning Datasets for LLMs
- Instruction Tuning: How to Train LLMs to Follow Instructions
- LoRA Fine-Tuning Tutorial: Train Custom LLMs on a Single GPU
- Fine-Tuning LLMs: Complete Guide
FAQ
Does synthetic data actually work for fine-tuning?
Yes — with quality controls. The Stanford Alpaca project showed that GPT-3-generated instruction data produces instruction-following models from scratch. More recent work (WizardLM, Orca, OpenHermes) has shown that GPT-4-generated data of sufficient quality can match or exceed human-annotated data for many tasks. The critical variable is filtering — unfiltered synthetic data consistently underperforms filtered synthetic data.
How do I prevent the fine-tuned model from inheriting GPT-4's style?
Two strategies: (1) Filter your generation prompt explicitly for GPT-4-specific patterns ("As an AI", "I cannot browse the internet") before training. (2) Mix synthetic data with some real human-written examples that establish the target style. The fine-tuned model's style is shaped by all training data — a 10% mix of real examples significantly influences the output style.
Is there a legal issue with using GPT-4-generated data to train another model?
OpenAI's terms of service currently prohibit using outputs to train models that compete with OpenAI's products. For non-competing models (domain-specific fine-tunes, open-source research), this is generally not a concern in practice. For commercial models intended to compete directly, consult legal counsel. Claude's terms have different provisions — check Anthropic's current usage policy.
How do I verify that synthetic data is factually accurate?
For factual domains: run the generated responses through a fact-checking step using a separate model call that specifically checks for factual errors. For code: execute the generated code in a sandbox and check for errors. For less verifiable content (writing style, strategy), rely on human auditing of samples. No automated filter catches all factual errors.