Semantic Search with Qdrant: Build a Search API That Works (2026)
A developer documentation site switched from Elasticsearch BM25 search to vector search and immediately saw a 40% drop in support ticket volume. Users were finding answers they could not before — because they were searching with their own words ("how do I stop the app from crashing on startup") not the documentation's words ("application lifecycle initialization error handling").
But the same team noticed that code-specific searches regressed. Searching for ConnectionError: max_retries — an exact error string — returned vaguely related conceptual docs instead of the specific troubleshooting page. Pure vector search had traded away precision for recall.
The production answer for most search use cases is neither pure keyword search nor pure vector search. It is hybrid search: BM25 for precision on exact terms, vector search for recall on semantic intent, combined with a re-ranker to get ordering right.
Concept Overview
Semantic search is the umbrella term for any search system that retrieves content by meaning rather than token overlap. Vector databases enable semantic search by converting the meaning-matching problem into a geometry problem — find the K vectors closest to the query vector in embedding space.
A complete semantic search system has four layers:
Retrieval — the fast, approximate layer that reduces your corpus from millions of documents to dozens of candidates. Uses ANN search (HNSW/IVF) for speed.
Filtering — structured predicates applied before or after vector search to constrain results by metadata (date range, category, user permissions). Most vector DBs support pre-filtering at the ANN level.
Re-ranking — a slower, more accurate model that takes the top 20–50 retrieved candidates and re-scores them. Cross-encoders are significantly more accurate than bi-encoders but too slow for retrieval.
Hybrid fusion — combining BM25 keyword scores with vector similarity scores using reciprocal rank fusion (RRF) or learned weights. This gives you exact-match precision and semantic recall in one result set.
In practice, starting with pure vector search and adding hybrid only when you identify specific query patterns where it helps is the right engineering approach.
How It Works
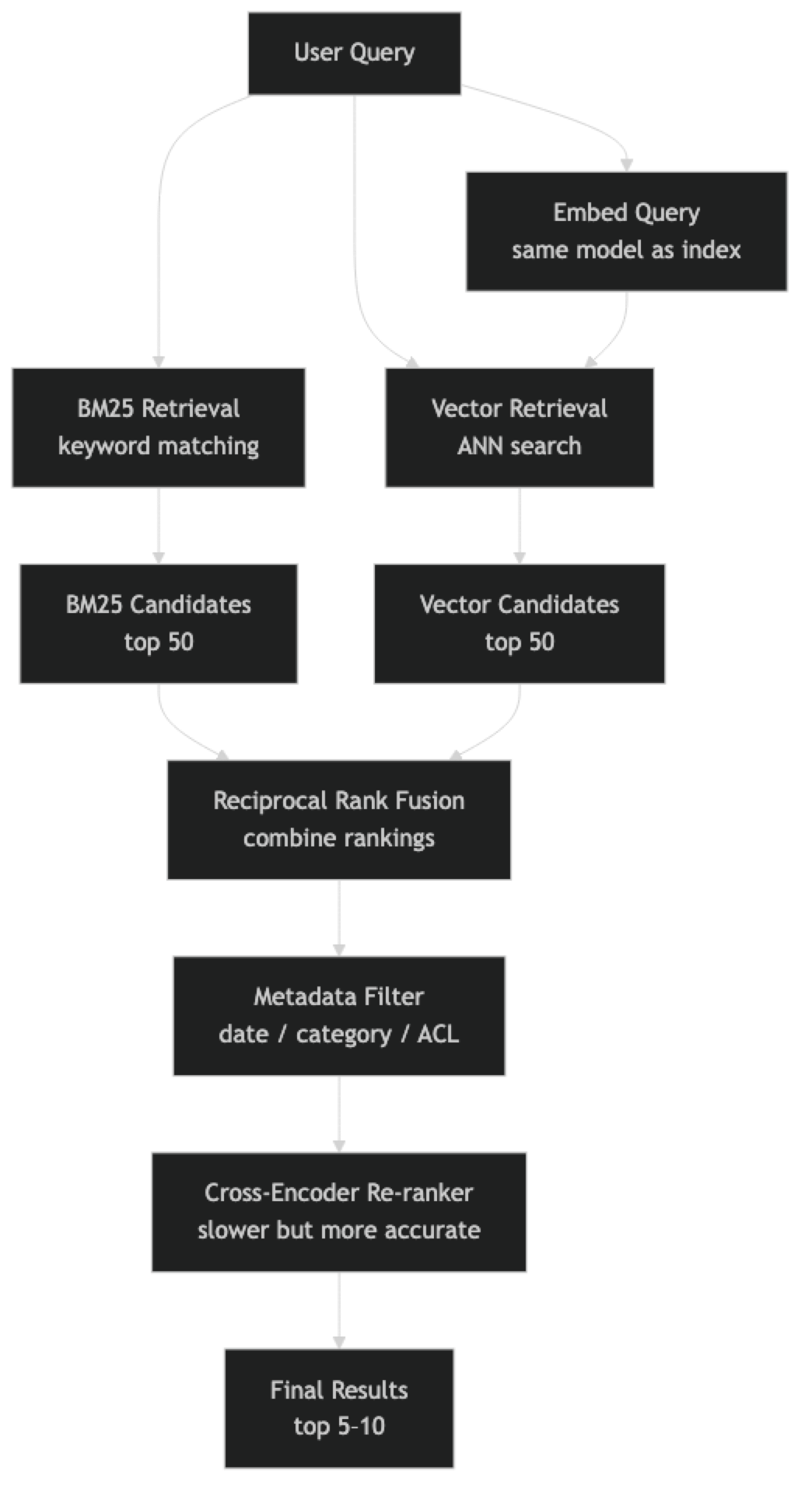
At query time, BM25 and vector retrieval run in parallel. Each returns a ranked list of candidates. RRF combines these rankings by summing the reciprocal of each document's rank in each list — a document ranked 1st in both lists scores very high; a document ranked 40th in both scores very low. RRF does not require calibrated scores, just rankings.
The re-ranker then takes the top 20–50 fused candidates and computes a more accurate relevance score using a cross-encoder model. Cross-encoders process the (query, document) pair together, allowing full attention between query and document tokens. This is significantly more accurate than bi-encoder similarity but prohibitively slow for full-corpus retrieval.
Implementation Example
Pure Vector Semantic Search with ChromaDB
pip install chromadb sentence-transformersimport chromadb
from chromadb.utils import embedding_functions
client = chromadb.PersistentClient(path="./semantic_search_db")
ef = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="BAAI/bge-base-en-v1.5" # better quality than small for search
)
collection = client.get_or_create_collection(
name="docs",
embedding_function=ef,
metadata={"hnsw:space": "cosine", "hnsw:M": 32},
)
# Index documents with metadata
documents = [
("d001", "How to handle ConnectionError max retries in Python requests", {"type": "troubleshooting", "product": "sdk"}),
("d002", "Python requests library timeout and retry configuration", {"type": "guide", "product": "sdk"}),
("d003", "Application startup initialization error handling best practices", {"type": "guide", "product": "core"}),
("d004", "Network connection troubleshooting for API integrations", {"type": "troubleshooting", "product": "api"}),
("d005", "Getting started with the Python SDK authentication flow", {"type": "guide", "product": "sdk"}),
("d006", "Rate limiting and backoff strategies for API clients", {"type": "guide", "product": "api"}),
]
collection.upsert(
ids=[d[0] for d in documents],
documents=[d[1] for d in documents],
metadatas=[d[2] for d in documents],
)
# Semantic search — finds by meaning
query = "app crashing when it tries to connect"
results = collection.query(
query_texts=[query],
n_results=3,
)
print(f"Query: '{query}'")
for doc, dist, meta in zip(
results["documents"][0],
results["distances"][0],
results["metadatas"][0],
):
print(f" [{1-dist:.3f}] {doc} ({meta['type']})")Hybrid Search with BM25 + Vector Re-ranking
pip install rank-bm25 sentence-transformers numpyimport numpy as np
from rank_bm25 import BM25Okapi
from sentence_transformers import SentenceTransformer, CrossEncoder
class HybridSearchEngine:
def __init__(
self,
bi_encoder_model: str = "BAAI/bge-base-en-v1.5",
cross_encoder_model: str = "cross-encoder/ms-marco-MiniLM-L-6-v2",
):
self.bi_encoder = SentenceTransformer(bi_encoder_model)
self.cross_encoder = CrossEncoder(cross_encoder_model)
self.documents: list[dict] = []
self.bm25: BM25Okapi | None = None
self.corpus_embeddings: np.ndarray | None = None
def index(self, docs: list[dict]) -> None:
"""Index documents with 'content' and optional metadata."""
self.documents = docs
texts = [d["content"] for d in docs]
# BM25 index
tokenized = [t.lower().split() for t in texts]
self.bm25 = BM25Okapi(tokenized)
# Vector index
self.corpus_embeddings = self.bi_encoder.encode(
texts,
normalize_embeddings=True,
batch_size=32,
show_progress_bar=len(docs) > 100,
)
def _vector_search(self, query: str, top_k: int) -> list[tuple[int, float]]:
q_vec = self.bi_encoder.encode([query], normalize_embeddings=True)[0]
scores = self.corpus_embeddings @ q_vec
indices = np.argsort(scores)[::-1][:top_k]
return [(int(i), float(scores[i])) for i in indices]
def _bm25_search(self, query: str, top_k: int) -> list[tuple[int, float]]:
scores = self.bm25.get_scores(query.lower().split())
indices = np.argsort(scores)[::-1][:top_k]
return [(int(i), float(scores[i])) for i in indices]
def _reciprocal_rank_fusion(
self,
vec_results: list[tuple[int, float]],
bm25_results: list[tuple[int, float]],
k: int = 60,
) -> list[tuple[int, float]]:
"""Combine ranked lists using Reciprocal Rank Fusion."""
scores: dict[int, float] = {}
for rank, (doc_id, _) in enumerate(vec_results):
scores[doc_id] = scores.get(doc_id, 0.0) + 1.0 / (k + rank + 1)
for rank, (doc_id, _) in enumerate(bm25_results):
scores[doc_id] = scores.get(doc_id, 0.0) + 1.0 / (k + rank + 1)
return sorted(scores.items(), key=lambda x: x[1], reverse=True)
def search(
self,
query: str,
top_k: int = 5,
retrieval_k: int = 20,
use_reranker: bool = True,
) -> list[dict]:
vec_results = self._vector_search(query, retrieval_k)
bm25_results = self._bm25_search(query, retrieval_k)
fused = self._reciprocal_rank_fusion(vec_results, bm25_results)
# Take top retrieval_k candidates for re-ranking
candidates = [self.documents[doc_id] for doc_id, _ in fused[:retrieval_k]]
if use_reranker and candidates:
# Cross-encoder scores (query, document) pairs
pairs = [(query, c["content"]) for c in candidates]
ce_scores = self.cross_encoder.predict(pairs)
ranked = sorted(zip(ce_scores, candidates), key=lambda x: x[0], reverse=True)
return [{"score": float(s), **doc} for s, doc in ranked[:top_k]]
else:
return [{"score": score, **self.documents[doc_id]}
for doc_id, score in fused[:top_k]]
# Usage
engine = HybridSearchEngine()
engine.index([
{"content": "ConnectionError max retries exceeded Python requests library", "type": "troubleshooting"},
{"content": "Python requests timeout retry configuration exponential backoff", "type": "guide"},
{"content": "Application startup initialization crash error handling", "type": "guide"},
{"content": "Network connection failure API integration debugging steps", "type": "troubleshooting"},
{"content": "Authentication flow token refresh OAuth2 Python SDK", "type": "guide"},
{"content": "Rate limiting 429 status code retry after header handling", "type": "guide"},
])
# Semantic query — no keyword overlap with any document
results = engine.search("app crashing when it tries to connect")
for r in results:
print(f"[{r['score']:.3f}] {r['content']} ({r['type']})")
print()
# Exact query — BM25 handles this precisely, vector confirms context
results = engine.search("ConnectionError max_retries")
for r in results:
print(f"[{r['score']:.3f}] {r['content']} ({r['type']})")Best Practices
Start with pure vector search, add hybrid only when you identify gaps. Hybrid search adds operational complexity. For most RAG and semantic search use cases, vector search alone gives excellent results. Build hybrid only when you have specific evidence — query logs showing precision failures on exact-match queries, for example.
Use a cross-encoder re-ranker for user-facing search. The bi-encoder gives fast retrieval; the cross-encoder gives accurate ordering. For a search interface where users see 5–10 results, the re-ranking quality improvement is immediately visible. Retrieve 20–50 candidates, re-rank with a cross-encoder, return top 5.
Filter before or after ANN search based on cardinality. If your metadata filter is highly selective (returns < 10% of the corpus), pre-filtering dramatically speeds up ANN search. If it is broad (returns > 50% of the corpus), post-filtering is more efficient. Most vector databases choose automatically, but verify for your data distribution.
Log queries and click-through data from day one. The fastest way to improve your semantic search is to know which queries are failing. Query logs showing zero-click results, reformulated queries, and negative feedback are more valuable than any benchmark.
For code search, combine a code-specific embedding model with BM25. General text embeddings handle natural language descriptions of code well but struggle with exact API names, error messages, and code syntax. microsoft/codebert-base or Salesforce/codet5p-110m-embedding give better code-specific recall.
Common Mistakes
Using cosine similarity thresholds from blog posts without domain-specific calibration. "Results below 0.7 are irrelevant" is a common heuristic that is wrong for most specific domains. Calibrate your threshold by sampling results at different scores and labeling their relevance manually.
Not handling the "no good results" case. Vector search always returns K results, even when all of them are bad. Implement a minimum similarity threshold and surface a "no results found" state rather than showing garbage results with high confidence.
Ignoring the embedding model's asymmetric query/passage format. BGE and E5 models are trained with asymmetric prompts — queries are prefixed with "query: " and documents with "passage: ". Omitting these prefixes during indexing or querying degrades retrieval quality by 5–15%.
# Correct for BGE/E5 models
query_embedding = model.encode(["query: " + user_query])
doc_embedding = model.encode(["passage: " + document_text])Running re-ranking on the full corpus instead of candidates. A cross-encoder scoring 1 million document pairs is a 1 million inference calls — this is minutes of compute, not milliseconds. Re-rank only the top 20–50 candidates from fast retrieval.
Key Takeaways
- Semantic search finds content by meaning rather than token overlap, using vector embeddings and ANN similarity search
- A production semantic search system has four layers: retrieval, filtering, re-ranking, and hybrid fusion
- Reciprocal Rank Fusion (RRF) combines BM25 and vector rankings without requiring calibrated score normalization
- Cross-encoder re-rankers are significantly more accurate than bi-encoder similarity but must only be applied to the top 20–50 candidates, not the full corpus
- BGE and E5 models require asymmetric query/passage prefixes — omitting them degrades retrieval quality by 5–15%
- Always implement a minimum similarity threshold — vector search always returns K results even when all are irrelevant
- Start with pure vector search and only add hybrid BM25 fusion when you have query logs showing exact-match precision failures
- Log queries and click-through data from day one — real user behavior is the most valuable signal for improving search quality
FAQ
What is reciprocal rank fusion and why use it instead of score normalization? RRF combines ranked lists based on document position, not raw score values. This matters because BM25 scores and cosine similarity scores are not on comparable scales — you cannot simply average them. RRF avoids the need to normalize scores across systems with different score distributions.
How much does re-ranking slow down search? A cross-encoder re-ranking 50 candidates on a CPU takes 50–200ms depending on document length and model size. On GPU, it is 5–20ms. For user-facing search where the total latency budget is 500ms, this is acceptable. For sub-50ms latency requirements, skip re-ranking or use a smaller cross-encoder model.
Can semantic search handle multi-language queries? Yes, with a multilingual embedding model. Index all documents with the multilingual model. Users can query in any supported language and retrieve documents in any other language, because all languages share the same embedding space.
What chunk size works best for semantic search? 256–512 tokens is the most common sweet spot. Shorter chunks (64–128 tokens) lose context; longer chunks (1024+ tokens) dilute the semantic signal. The optimal size depends on your document structure — technical documentation with short, focused sections does well at 128–256 tokens.
When should I use hybrid search instead of pure vector search? Add hybrid search when you have evidence from query logs that exact-match queries are failing. Common failure modes: product names, error codes, version numbers, proper nouns, and technical identifiers. If more than 15–20% of your queries contain these patterns, hybrid search provides a measurable improvement.
What is the difference between pre-filtering and post-filtering in vector search? Pre-filtering applies metadata constraints before the ANN search, reducing the candidate set the search operates on. Post-filtering applies constraints to the ANN results after retrieval. Pre-filtering is faster for highly selective filters (under 10% of corpus); post-filtering avoids narrowing the ANN search graph and is better for broad filters.
How do I know if my semantic search quality is good enough? Build a golden test set of 50–100 real queries with known correct answers. Measure recall@K (what fraction of the time is the correct answer in the top K results). A recall@5 below 70% indicates retrieval needs significant improvement. Track this metric across deployments as a regression guard.