LLM Evaluation: Test Real Quality, Not Benchmark Scores (2026)
LLM Evaluation: How to Test and Score Language Model Quality (2026)
Last updated: March 2026
The most common evaluation mistake in LLM projects is measuring the wrong thing. A fine-tuned model with excellent perplexity scores can fail completely at the actual task. A model that scores high on automated BLEU metrics can produce outputs that humans find useless. Conversely, a model that looks excellent in casual testing can fail on a systematic benchmark.
Evaluation is not one problem — it is several. You need metrics for training monitoring (perplexity, validation loss), metrics for capability measurement (benchmarks like MMLU, MT-Bench), and metrics for production quality (task-specific evals, LLM-as-judge). Each serves a different purpose and none is a substitute for the others.
A common mistake I've seen in production systems is shipping a fine-tuned model based solely on "it looks good in demos" without any systematic evaluation. The failure mode appears weeks later when an edge case surfaces that the demo testing never covered.
Concept Overview
Perplexity measures how well the model predicts the next token in a test set. Lower is better. It is a proxy for language modeling quality but does not measure task-specific performance. A model with perplexity 5 might still generate factually wrong or unhelpful answers.
BLEU (Bilingual Evaluation Understudy) measures n-gram overlap between generated text and reference text. Originally designed for machine translation, it is now used more broadly but has significant limitations: it rewards literal similarity over semantic correctness and is sensitive to synonym choice.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) measures overlap from the recall perspective. ROUGE-1 measures unigram overlap, ROUGE-2 bigram overlap, ROUGE-L longest common subsequence. More commonly used for summarization than generation.
LLM-as-judge uses a capable model (GPT-4, Claude) to score outputs on dimensions like correctness, helpfulness, format adherence, and safety. Correlates well with human preferences, scales to arbitrary tasks, and can provide explanations. The main risk is judge bias and consistency.
Task-specific evals measure the metric that actually matters — format adherence for structured output tasks, accuracy for QA tasks, code execution pass rate for code generation. These require custom implementation but are the most reliable signal.
Benchmark suites (lm-eval-harness, MMLU, MT-Bench) provide standardized tasks for comparing models. Essential for tracking regression when fine-tuning, since fine-tuned models often degrade on tasks not in the training set.
How It Works
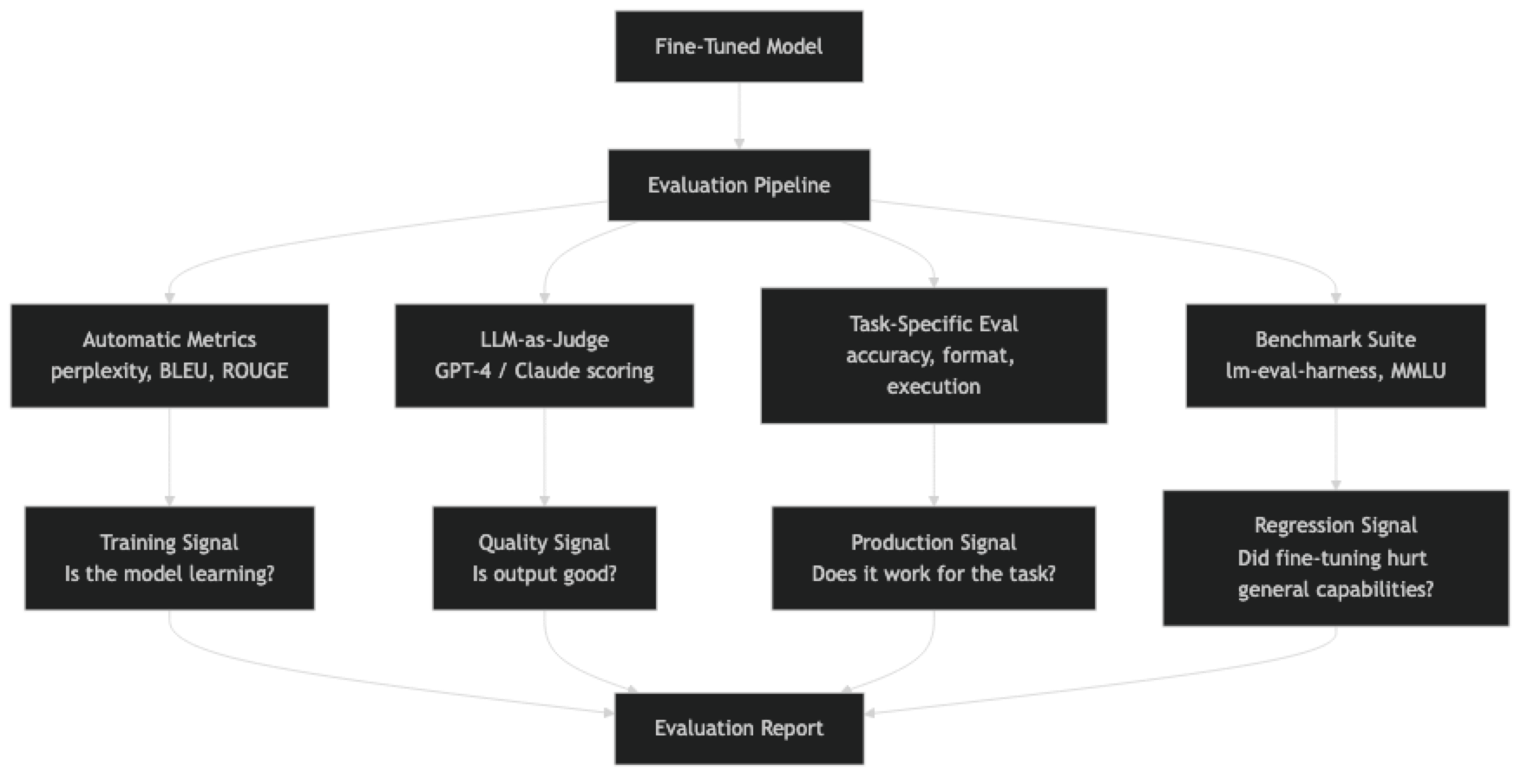
The right evaluation strategy depends on where you are in the development cycle. During training, track perplexity. After training, run task-specific evals and a regression benchmark. Before shipping, use LLM-as-judge for qualitative scoring on diverse test prompts.
Implementation Example
Perplexity on a Test Set
import torch
import math
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import Dataset
def compute_perplexity(model, tokenizer, texts, max_length=512, batch_size=4):
"""Compute perplexity on a list of text strings."""
model.eval()
total_loss = 0
total_tokens = 0
for i in range(0, len(texts), batch_size):
batch = texts[i:i + batch_size]
encodings = tokenizer(
batch,
return_tensors="pt",
padding=True,
truncation=True,
max_length=max_length,
).to(model.device)
with torch.no_grad():
outputs = model(
**encodings,
labels=encodings["input_ids"],
)
# outputs.loss is mean cross-entropy over non-padding tokens
loss = outputs.loss.item()
# Weight by number of non-padding tokens
n_tokens = encodings["attention_mask"].sum().item()
total_loss += loss * n_tokens
total_tokens += n_tokens
avg_loss = total_loss / total_tokens
perplexity = math.exp(avg_loss)
return perplexity
# Load model and tokenizer
model_path = "./merged-model"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path, torch_dtype=torch.bfloat16, device_map="auto"
)
# Compute perplexity on evaluation set
eval_texts = [example["text"] for example in eval_dataset]
ppl = compute_perplexity(model, tokenizer, eval_texts)
print(f"Perplexity: {ppl:.2f}")BLEU and ROUGE Scoring
from nltk.translate.bleu_score import corpus_bleu, SmoothingFunction
from rouge_score import rouge_scorer
import numpy as np
def compute_bleu(hypotheses, references):
"""
Compute corpus BLEU score.
hypotheses: list of generated strings
references: list of reference strings
"""
tokenized_hyps = [h.lower().split() for h in hypotheses]
tokenized_refs = [[r.lower().split()] for r in references] # Double-nested list
smoother = SmoothingFunction().method1 # Avoid 0 for short sequences
score = corpus_bleu(tokenized_refs, tokenized_hyps, smoothing_function=smoother)
return score
def compute_rouge(hypotheses, references):
"""Compute ROUGE-1, ROUGE-2, ROUGE-L scores."""
scorer = rouge_scorer.RougeScorer(['rouge1', 'rouge2', 'rougeL'], use_stemmer=True)
scores = {"rouge1": [], "rouge2": [], "rougeL": []}
for hyp, ref in zip(hypotheses, references):
result = scorer.score(ref, hyp)
for key in scores:
scores[key].append(result[key].fmeasure)
return {k: np.mean(v) for k, v in scores.items()}
# Generate outputs and evaluate
hypotheses = []
references = []
for example in test_examples:
messages = example["messages"][:-1] # Input messages without the last assistant turn
inputs = tokenizer.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True, return_tensors="pt"
).to(model.device)
with torch.no_grad():
output = model.generate(inputs, max_new_tokens=256, temperature=0.0)
generated = tokenizer.decode(output[0][inputs.shape[1]:], skip_special_tokens=True)
hypotheses.append(generated)
references.append(example["messages"][-1]["content"])
bleu = compute_bleu(hypotheses, references)
rouge = compute_rouge(hypotheses, references)
print(f"BLEU: {bleu:.4f}")
print(f"ROUGE-1: {rouge['rouge1']:.4f}, ROUGE-2: {rouge['rouge2']:.4f}, ROUGE-L: {rouge['rougeL']:.4f}")LLM-as-Judge Evaluation
from openai import OpenAI
import json
client = OpenAI()
JUDGE_PROMPT = """You are evaluating the quality of an AI assistant's response.
Task: {task_description}
User question: {question}
Model response: {response}
Reference answer: {reference}
Rate the response on the following dimensions (1-5 scale):
1. Correctness: Is the information accurate and complete?
2. Helpfulness: Does it actually answer what was asked?
3. Format: Is the structure and format appropriate?
4. Conciseness: Is it appropriately concise without being too brief?
Respond in JSON format:
{{
"correctness": <1-5>,
"helpfulness": <1-5>,
"format": <1-5>,
"conciseness": <1-5>,
"overall": <1-5>,
"reasoning": "<brief explanation>"
}}"""
def llm_judge(question, response, reference, task_description, model="gpt-4o"):
"""Score a model response using an LLM judge."""
prompt = JUDGE_PROMPT.format(
task_description=task_description,
question=question,
response=response,
reference=reference,
)
completion = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
response_format={"type": "json_object"},
)
return json.loads(completion.choices[0].message.content)
# Run LLM-as-judge evaluation
task_description = "Customer support for an e-commerce platform"
judge_results = []
for i, (hyp, ref, example) in enumerate(zip(hypotheses, references, test_examples)):
question = next(
m["content"] for m in example["messages"] if m["role"] == "user"
)
scores = llm_judge(question, hyp, ref, task_description)
judge_results.append(scores)
print(f"Example {i+1}: overall={scores['overall']}/5 — {scores['reasoning'][:80]}...")
# Aggregate
overall_scores = [r["overall"] for r in judge_results]
print(f"\nMean overall score: {np.mean(overall_scores):.2f}/5")
print(f"Correctness: {np.mean([r['correctness'] for r in judge_results]):.2f}")
print(f"Helpfulness: {np.mean([r['helpfulness'] for r in judge_results]):.2f}")Running lm-eval-harness Benchmarks
# Install
pip install lm-eval
# Run standard benchmarks on your fine-tuned model
lm_eval --model hf \
--model_args pretrained=./merged-model,dtype=bfloat16 \
--tasks mmlu,hellaswag,winogrande \
--device cuda:0 \
--batch_size 8 \
--output_path ./eval_results/
# Compare with base model to detect regression
lm_eval --model hf \
--model_args pretrained=meta-llama/Meta-Llama-3-8B-Instruct,dtype=bfloat16 \
--tasks mmlu,hellaswag,winogrande \
--device cuda:0 \
--batch_size 8 \
--output_path ./eval_results/base/# Parse and compare results
import json
def load_eval_results(path):
with open(f"{path}/results.json") as f:
return json.load(f)
base_results = load_eval_results("./eval_results/base")
ft_results = load_eval_results("./eval_results")
tasks = ["mmlu", "hellaswag", "winogrande"]
print(f"{'Task':<20} {'Base':>10} {'Fine-tuned':>12} {'Delta':>8}")
print("-" * 52)
for task in tasks:
base_acc = base_results["results"][task]["acc,none"]
ft_acc = ft_results["results"][task]["acc,none"]
delta = ft_acc - base_acc
delta_str = f"+{delta:.3f}" if delta >= 0 else f"{delta:.3f}"
print(f"{task:<20} {base_acc:>10.3f} {ft_acc:>12.3f} {delta_str:>8}")Task-Specific Evaluation: Format Adherence
import re
import json as json_module
def evaluate_json_format_adherence(model, tokenizer, test_prompts):
"""Evaluate whether model outputs valid JSON when asked."""
results = {"valid_json": 0, "invalid_json": 0, "examples": []}
for prompt in test_prompts:
messages = [
{"role": "system", "content": "You respond only with valid JSON."},
{"role": "user", "content": prompt},
]
inputs = tokenizer.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True, return_tensors="pt"
).to(model.device)
with torch.no_grad():
output = model.generate(inputs, max_new_tokens=256, temperature=0.0)
response = tokenizer.decode(output[0][inputs.shape[1]:], skip_special_tokens=True)
# Check if output is valid JSON
try:
parsed = json_module.loads(response.strip())
results["valid_json"] += 1
valid = True
except json_module.JSONDecodeError:
results["invalid_json"] += 1
valid = False
results["examples"].append({"prompt": prompt, "response": response, "valid": valid})
total = results["valid_json"] + results["invalid_json"]
adherence_rate = results["valid_json"] / total
print(f"JSON format adherence: {adherence_rate:.1%} ({results['valid_json']}/{total})")
return resultsBest Practices
Always compare your fine-tuned model against the base model on a general benchmark. Fine-tuning often degrades general capabilities — this is called catastrophic forgetting. Running MMLU or HellaSwag on both the base and fine-tuned model before deploying tells you exactly how much general capability was lost.
Use LLM-as-judge with the same judge model consistently. Different judge models have different biases. GPT-4o and Claude 3.5 Sonnet produce different relative rankings. Pick one and use it throughout your evaluation — the absolute scores matter less than the relative comparisons.
Calibrate your LLM-as-judge by comparing its scores to human ratings. On a sample of 50–100 outputs, have humans rate quality on the same scale. If judge scores and human scores correlate at r > 0.8, the judge is reliable. If not, adjust your judge prompt or switch models.
Run evaluations before and after every training change. Learning rate, rank, dataset modification — any change can affect quality in unexpected ways. A systematic eval before and after each change is the only way to isolate what matters.
Common Mistakes
Treating perplexity as a proxy for task quality. Perplexity measures language modeling. A model can have excellent perplexity on the eval set while consistently generating wrong answers to domain questions. Task-specific evaluation is non-negotiable.
Using BLEU for open-ended generation tasks. BLEU was designed for machine translation where there is a clear reference. For open-ended generation (QA, creative writing, code), BLEU scores are near-meaningless. Use LLM-as-judge instead.
Evaluating on the training distribution only. If your test set is drawn from the same source as your training set, evaluation scores are optimistic. Always hold out examples that represent real production inputs — not just examples from your dataset.
Not versioning evaluation artifacts. When you run an evaluation, save the model path, dataset version, prompt templates, and results together. Without this, it is impossible to reproduce or compare results from different experiments.
Trusting a single LLM-as-judge call per example. LLM judge outputs have variance. For critical comparisons, run each example through the judge 3 times and average the scores, or use majority voting for categorical judgments.
Summary
Effective LLM evaluation requires multiple complementary metrics. Perplexity and validation loss monitor training progress. Task-specific metrics measure whether the model achieves the actual goal. LLM-as-judge provides scalable qualitative assessment. Benchmark suites detect capability regression. No single metric is sufficient — the combination gives a reliable picture of model quality.
The most common evaluation mistake is shipping based on informal testing. Invest in a systematic evaluation pipeline early in the project. It will catch problems before they reach users and give you the feedback loop needed to improve the model iteratively.
Related Articles
- LLM Fine-Tuning Guide: LoRA, QLoRA, and Full Fine-Tuning — Fine-tuning pipeline including evaluation
- RAG Evaluation — Evaluation techniques specific to retrieval-augmented systems
- RLHF Explained — How human preference data improves alignment
- Dataset Preparation for LLM Fine-Tuning — Building evaluation sets alongside training data
- Synthetic Data for LLM Training — Generating diverse evaluation examples
FAQ
What is a good perplexity score for a fine-tuned LLM?
Perplexity is relative — it depends on the domain, sequence length, and tokenizer. What matters is the trajectory: perplexity should decrease during training and then plateau. If perplexity is decreasing on training data but increasing on eval data, you are overfitting. Compare relative to the base model's perplexity on the same eval set.
How many test examples do I need for reliable evaluation?
For LLM-as-judge evaluation, 100–200 examples gives statistically stable averages (within 2–3% margin of error). For binary metrics like format adherence, 50–100 examples is often enough. For benchmark suites like MMLU, each task has hundreds of multiple-choice questions built in.
How do I detect if my LLM judge has systematic bias?
Create a "position bias test": run the same pair with chosen and rejected responses swapped. If the judge consistently scores the first-presented response higher regardless of content, you have position bias. Mitigate by averaging scores from both orderings.
Can I use the fine-tuned model as its own judge?
Only if it is substantially more capable than the model being evaluated. Typically, you want a more capable model (GPT-4o, Claude 3.5 Sonnet) judging a smaller fine-tuned model. Using the same model as judge creates a self-serving bias where the model favors its own style.