LLM Benchmarks: Why High Scores Still Fail Your Use Case (2026)
LLM Benchmarks Explained: MMLU, HumanEval, GPQA & What They Mean (2026)
Last updated: March 2026
Every model release announcement leads with benchmark scores. Llama 3.3 70B scores 86 on MMLU. Qwen2.5 72B scores 87.2. Phi-4 achieves "GPT-4 class" performance on MATH at 14B parameters. These numbers are real — but they tell a narrower story than the marketing copy implies, and engineering decisions made purely on published benchmarks tend to produce disappointment when the model meets your actual data.
Benchmarks are useful tools that have been pushed past their useful range. They were designed to measure general capability across diverse tasks. They are now used to justify marketing claims, drive HuggingFace leaderboard positions, and influence purchasing decisions for use cases the benchmarks never measured. Understanding what each benchmark actually tests — and what it does not test — is what separates engineers who can read a model card critically from those who are surprised when the "state-of-the-art" model fails their application.
This guide covers the benchmarks you will encounter most, what they measure, how they are gamed, and how to build an internal evaluation suite that actually reflects your application's requirements.
Concept Overview
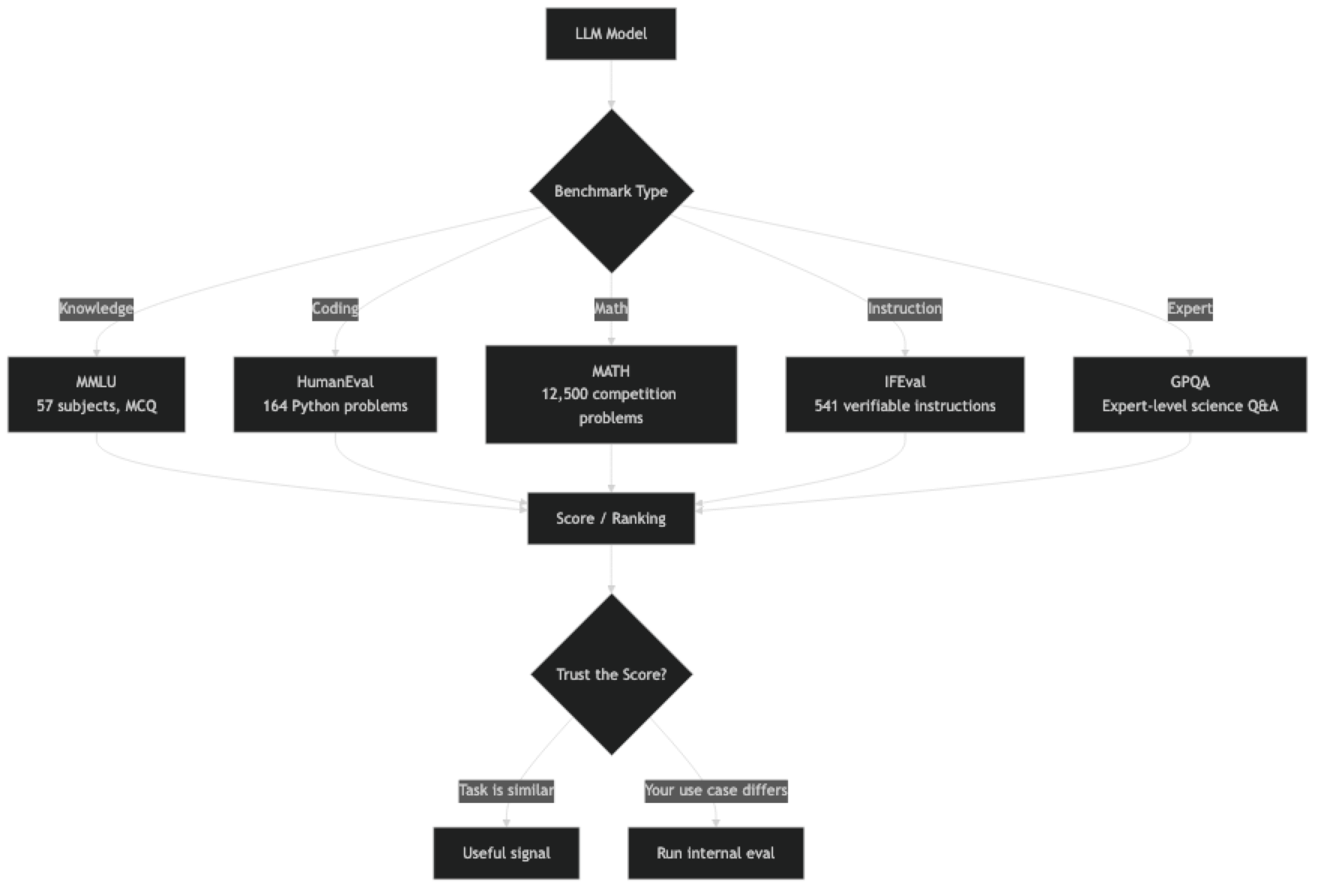
LLM benchmarks fall into roughly three categories:
Knowledge and reasoning — Tests that measure the model's breadth of factual knowledge and reasoning ability. MMLU, GPQA, ARC-Challenge.
Coding — Tests that evaluate code generation correctness, typically by running generated code against test cases. HumanEval, MBPP, SWE-bench.
Math and formal reasoning — Benchmarks measuring step-by-step mathematical reasoning. MATH, GSM8K, AIME.
Instruction following — Tests that measure whether the model follows detailed, constrained instructions correctly. IFEval, MT-Bench.
Real-world task performance — Benchmarks that approximate actual use. SWE-bench (software engineering), MMLU-Pro, GPQA-Diamond.
The score you should care most about depends entirely on your use case. A high MATH score is irrelevant if your application is customer support chat.
How It Works
Key Benchmarks Explained
MMLU (Massive Multitask Language Understanding)
MMLU covers 57 subjects spanning STEM, humanities, social sciences, and professional domains (law, medicine, finance). Each question is a 4-option multiple choice. The dataset has roughly 14,000 test questions.
A score of 86 means the model answered 86% of questions correctly. For reference, human experts in individual domains score 89–92%; general human performance is around 70%.
What it measures well: Breadth of factual knowledge, basic reasoning across diverse domains.
What it does not measure: Instruction following, code generation, practical task completion, long-form reasoning, or how well the model performs on your domain.
The saturation problem: Top models now score 85–90% on MMLU. The benchmark is approaching ceiling performance, making it increasingly useless for differentiating between frontier models. A 1-point MMLU difference between two models is noise.
HumanEval
HumanEval contains 164 Python programming problems with unit test suites. The model generates code, which is then executed against the tests. The primary metric is pass@1 — the fraction of problems solved on the first try.
A score of 88 on HumanEval means the model correctly solved 88% of problems on the first attempt.
What it measures well: Basic algorithmic Python coding ability.
What it does not measure: Large codebase comprehension, debugging, code review, complex multi-file implementations, or real-world SWE tasks. The problems are algorithmic puzzles, not production software challenges.
The gaming problem: Models trained on HumanEval-adjacent data memorize problem patterns. A model that scores 90 on HumanEval but 50 on fresh, held-out coding problems has been optimized for the benchmark, not for real coding.
MATH
The MATH benchmark has 12,500 competition mathematics problems across six difficulty levels (1–5), covering algebra, counting, geometry, number theory, and probability. Problems require multi-step formal reasoning, not just recalling facts.
What it measures well: Multi-step mathematical reasoning, symbolic manipulation, formal problem-solving.
What it does not measure: Applied math, engineering calculations, or domain-specific quantitative reasoning.
MATH is one of the least saturated major benchmarks. The performance spread between models remains wide (40–90%), making it a better discriminator than MMLU for reasoning capability.
MT-Bench
MT-Bench is a multi-turn conversation benchmark with 80 hand-crafted questions across 8 categories: writing, roleplay, reasoning, math, coding, extraction, STEM, and humanities. Model responses are evaluated by GPT-4 on a 1–10 scale.
What it measures well: Conversational quality, multi-turn coherence, instruction following in chat contexts.
The bias problem: Because GPT-4 evaluates responses, MT-Bench has a systematic bias toward GPT-4's stylistic preferences — verbose, structured responses. Models that produce concise, direct answers may be underrated even if the content is correct.
GPQA (Graduate-Level Google-Proof Q&A)
GPQA contains 448 multiple-choice questions designed to be difficult even for domain experts. Questions are written by PhD-level researchers in biology, chemistry, and physics, and are verified to be correct by independent experts. Google searches do not help — the questions require genuine expert understanding.
GPQA-Diamond (198 questions) is the hardest subset. PhD-level human experts score around 65–70%. Models scoring above 75% on GPQA-Diamond are approaching genuine scientific reasoning capability.
What it measures well: Expert-level scientific reasoning, beyond-memorization problem solving.
What it does not measure: Most production use cases. GPQA is useful for identifying frontier models; it is not a practical benchmark for most applications.
IFEval (Instruction Following Evaluation)
IFEval contains 541 prompts with verifiable, precise instructions: "Write a 3-paragraph response where each paragraph starts with the letter A," or "Respond in JSON with exactly these 5 fields." Performance is scored programmatically — no LLM judge required.
What it measures well: Constrained generation, format following, rule adherence.
What it does not measure: Open-ended quality. A model can score 90 on IFEval and still produce mediocre prose or code.
IFEval is underrated in production contexts. Many real-world failures are not capability failures — the model understood the question but did not follow the output format specification. IFEval performance is a reasonable proxy for this.
Implementation Example
Running Evaluations with lm-eval-harness
# Install the evaluation harness
pip install lm-eval
# Evaluate a local Ollama model
lm_eval --model local-completions \
--model_args model=llama3.1:8b,base_url=http://localhost:11434/v1 \
--tasks mmlu,hellaswag,arc_challenge \
--num_fewshot 5 \
--output_path ./eval_results
# Evaluate a HuggingFace model directly
lm_eval --model hf \
--model_args pretrained=meta-llama/Llama-3.1-8B-Instruct \
--tasks humaneval \
--num_fewshot 0 \
--output_path ./eval_resultsBuilding an Internal Evaluation Suite
import json
import time
from dataclasses import dataclass, field
from typing import Callable
import ollama
@dataclass
class EvalCase:
"""A single evaluation test case."""
id: str
prompt: str
expected_output: str = ""
grader: str = "contains" # "contains", "exact", "llm", "custom"
metadata: dict = field(default_factory=dict)
@dataclass
class EvalResult:
case_id: str
model: str
response: str
passed: bool
latency_s: float
score: float # 0.0 to 1.0
def grade_contains(response: str, expected: str) -> float:
"""Pass if expected substring appears in response."""
return 1.0 if expected.lower() in response.lower() else 0.0
def grade_exact(response: str, expected: str) -> float:
"""Pass only on exact match (case-insensitive, stripped)."""
return 1.0 if response.strip().lower() == expected.strip().lower() else 0.0
def grade_json_valid(response: str, expected: str = "") -> float:
"""Pass if response is valid JSON."""
try:
json.loads(response.strip())
return 1.0
except json.JSONDecodeError:
return 0.0
def run_eval_suite(
model: str,
cases: list[EvalCase],
graders: dict[str, Callable] = None,
) -> dict:
"""Run a full evaluation suite and return aggregate results."""
if graders is None:
graders = {
"contains": grade_contains,
"exact": grade_exact,
"json_valid": grade_json_valid,
}
results = []
for case in cases:
start = time.time()
response = ollama.chat(
model=model,
messages=[{"role": "user", "content": case.prompt}]
)["message"]["content"]
latency = time.time() - start
grader_fn = graders.get(case.grader, grade_contains)
score = grader_fn(response, case.expected_output)
results.append(EvalResult(
case_id=case.id,
model=model,
response=response,
passed=score >= 0.5,
latency_s=round(latency, 2),
score=score,
))
# Aggregate metrics
total = len(results)
passed = sum(1 for r in results if r.passed)
avg_latency = sum(r.latency_s for r in results) / total
return {
"model": model,
"total_cases": total,
"passed": passed,
"pass_rate": round(passed / total, 3),
"avg_latency_s": round(avg_latency, 2),
"results": results,
}
# Example evaluation suite for a JSON extraction task
extraction_cases = [
EvalCase(
id="extract_001",
prompt='Extract the name and email from: "Contact John Doe at john.doe@example.com" Return only valid JSON.',
expected_output="",
grader="json_valid",
),
EvalCase(
id="extract_002",
prompt='What is the capital of France? Reply with just the city name.',
expected_output="Paris",
grader="exact",
),
EvalCase(
id="extract_003",
prompt="List 3 Python web frameworks.",
expected_output="flask",
grader="contains",
),
]
# Run on multiple models
for model in ["llama3.1:8b", "mistral:7b-instruct", "phi4:14b"]:
result = run_eval_suite(model, extraction_cases)
print(f"\n{result['model']}: {result['pass_rate']:.0%} pass rate, "
f"{result['avg_latency_s']}s avg latency")Benchmark Gaming and What to Watch For
Benchmark contamination — where test data appears in training data — is a known problem across the entire field. HumanEval problems, MMLU questions, and MATH problems have appeared in web crawls that form training data. A model that scores 90 on HumanEval might have been partially trained on the HumanEval test set. This is difficult to verify and rarely disclosed.
Warning signs that a model's benchmark scores may be inflated:
- Large performance gaps between a model and all comparable-size models from other labs
- Strong benchmark performance with weak qualitative performance in actual use
- Lab reluctance to release training data details
- Performance specifically strong on public benchmarks but weak on held-out variants
The practical response is to maintain your own internal evaluation set built from real production examples. Benchmark scores help you create an initial short list; your internal eval is what makes the final decision.
Best Practices
Build your own eval set before picking a model. Take 50–100 examples from your actual production use case — real queries, edge cases, failure modes you have observed. This is 2–3 hours of work and pays dividends every time you evaluate a new model.
Separate your eval set from your development prompts. If you tune your system prompt against the same examples you use for evaluation, you are overfitting to your eval set. Keep a held-out test split.
Use automated graders where possible. Programmatic graders (exact match, contains, JSON validity, regex) are faster, cheaper, and more reproducible than LLM-judge graders. Only use LLM evaluation for tasks where programmatic grading is genuinely impossible.
Report latency alongside quality. A model with 95% accuracy at 5 tok/s may be worse for your application than a model with 88% accuracy at 40 tok/s. Benchmark tables never include latency for your specific hardware.
Common Mistakes
Using MMLU as a proxy for coding ability. MMLU has no coding questions. A model scoring 90 on MMLU can have mediocre code generation. Check HumanEval or run your own coding eval.
Comparing pass@1 scores across different temperatures. HumanEval pass@1 scores are highly temperature-sensitive. Scores reported at different temperatures are not directly comparable.
Treating MT-Bench as an objective quality measure. MT-Bench scores reflect GPT-4's stylistic preferences. Models that are more concise or use different formatting may score lower despite equal or better content quality.
Not accounting for few-shot vs zero-shot differences. Most benchmarks are run 5-shot (with 5 examples in the prompt). Zero-shot performance can differ significantly. Always verify the evaluation setup when comparing scores across different publications.
Ignoring benchmark-specific caveats in model cards. Most model cards note which benchmark versions were used and any known contamination concerns. Skipping the model card means missing important context for interpreting scores.
Key Takeaways
- Benchmark scores are directional signals, not ground truth — a model scoring high on MMLU can still fail your specific task
- MMLU measures broad factual knowledge across 57 subjects; it is near-saturation at the frontier and a poor discriminator between top models
- HumanEval measures Python coding on 164 algorithmic problems — it does not measure real-world software engineering ability
- MATH is the least saturated major benchmark and the best discriminator for multi-step reasoning capability
- IFEval is underrated for production use — it measures constrained instruction following, which is a common failure mode in real applications
- Benchmark contamination (training on test data) is a known, widespread problem — always verify scores against your own held-out evaluation
- Build an internal eval set of 50–100 representative examples from your actual workload before selecting a model for production
- Latency and throughput are never included in public benchmark tables — always measure them on your target hardware
FAQ
Which benchmark best predicts real-world coding performance? SWE-bench is the closest to real software engineering tasks, but it is expensive to run. For practical evaluation, HumanEval provides a reasonable proxy for basic code generation. Build your own coding eval with examples from your actual codebase for the most reliable signal.
Is a model that scores 80 on MMLU twice as good as one scoring 40? No. MMLU scores are not linearly meaningful. A score of 40% is near-random performance for a 4-option multiple choice test, while 80% represents strong performance. The relevant comparison range for frontier models is roughly 70–90%. Above 90% is near-ceiling and less meaningful.
How do I know if a model has been trained on benchmark data? You often cannot verify this definitively. Red flags include suspiciously high performance on public benchmarks with weak qualitative performance, and labs that do not publish training data details. Run your own held-out evaluation as the most reliable check.
What is a good internal eval set size? 50 cases is the minimum for a meaningful signal. 100–200 cases per task type gives you reliable pass rates. More than 500 is generally overkill for model selection decisions — invest that time in diversifying examples, not adding more of the same.
Why does MT-Bench have a bias problem? MT-Bench responses are evaluated by GPT-4, which introduces a systematic bias toward GPT-4's preferred response style — verbose and structured. Models that produce concise, direct answers may score lower even when their content quality is equal or better.
What is GPQA-Diamond and when should I use it? GPQA-Diamond is 198 graduate-level multiple choice questions written by PhD researchers in biology, chemistry, and physics. PhD-level human experts score around 65–70%. It is useful for identifying frontier-level reasoning capability but is not relevant for most production application selection decisions.
How do I run my own evaluations?
Use the lm-eval-harness library from EleutherAI. It supports most standard benchmarks and can evaluate Ollama models, HuggingFace models, and API models. For custom evaluations, build a Python eval harness using the pattern in the implementation example above.