LLM API Errors: Fix Rate Limits and 429s for Good (2026)
LLM API Error Handling: Retries, Rate Limits & Fallbacks in Python (2026)
Last updated: March 2026
LLM API errors fall into two categories: the ones developers handle in their first week (rate limits, auth failures) and the ones that bite them in production three months later (context length exceeded with user data, content filter triggering on legitimate business queries, cascade failures during provider outages).
The second category is where most production incidents come from. The error types are predictable — the HTTP status codes and error classes are documented by every provider. What is less documented is how these errors interact with real application flows: what happens to the user's in-progress action, whether the error is retryable or fatal, and how to design fallback behavior that degrades gracefully rather than crashing.
This guide covers every significant error type you will encounter with OpenAI, Anthropic, and Gemini, with concrete handling code for each.
Concept Overview
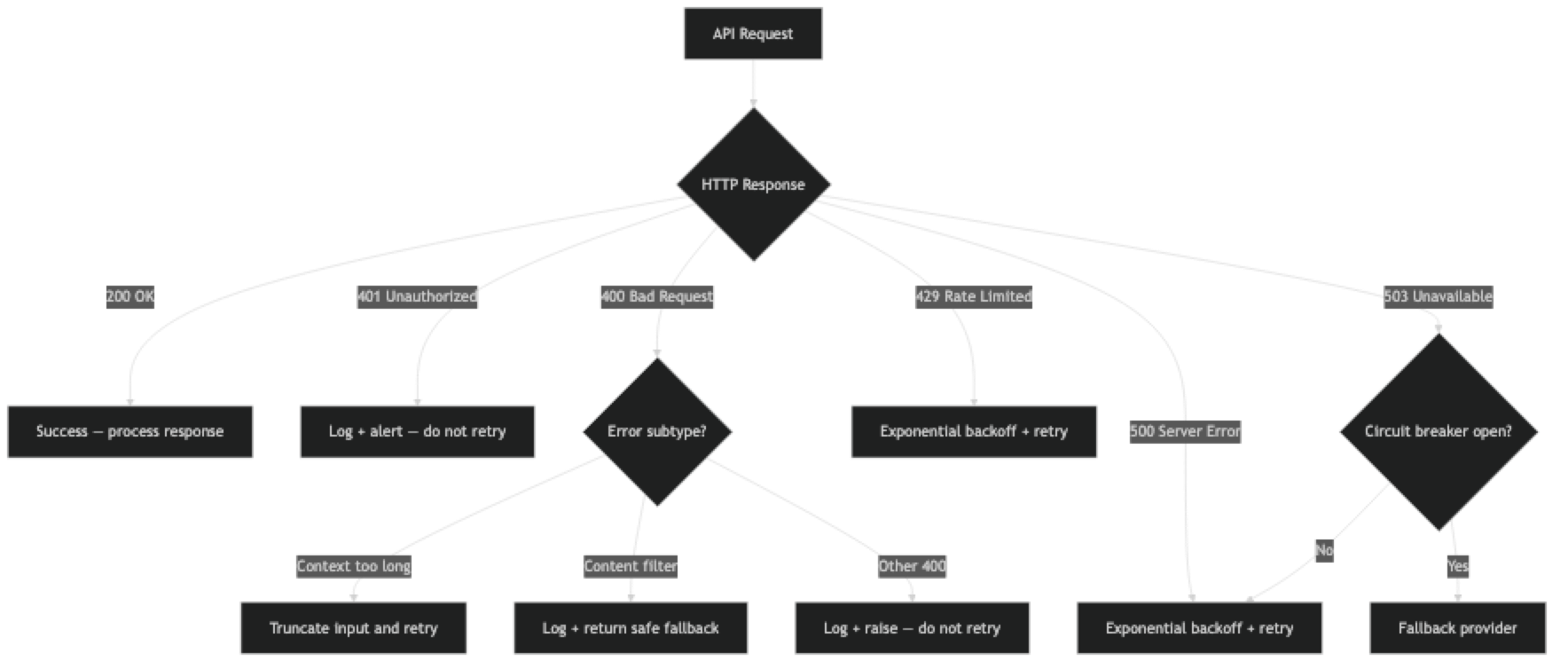
LLM API errors group into four categories:
| Category | HTTP Status | Retryable? | Examples |
|---|---|---|---|
| Client errors | 400, 401, 422 | No | Invalid request, bad API key, malformed JSON |
| Rate limits | 429 | Yes (with backoff) | TPM/RPM exceeded |
| Context errors | 400 | Partially | Context length exceeded, content filtered |
| Server errors | 500, 503 | Yes (with backoff) | Provider outage, internal error |
The key insight: only server errors and rate limits are reliably retryable. Client errors (bad request, auth failure, malformed schema) will fail again on retry. Context and content filter errors require changing the request, not retrying the same one.
Common OpenAI error types:
RateLimitError— 429, retry with backoffAuthenticationError— 401, fix API keyBadRequestError— 400, fix the requestAPITimeoutError— Request timed out, retryAPIConnectionError— Network issue, retryInternalServerError— 500, retry with backoff
How It Works
Implementation Example
Comprehensive Error Handler
import time
import random
import logging
from openai import (
OpenAI,
AuthenticationError,
BadRequestError,
RateLimitError,
APITimeoutError,
APIConnectionError,
InternalServerError,
UnprocessableEntityError,
)
logger = logging.getLogger(__name__)
client = OpenAI()
class LLMError(Exception):
"""Base class for LLM-related errors in our application."""
pass
class ContentFilterError(LLMError):
"""Request was blocked by content filter."""
pass
class ContextLengthError(LLMError):
"""Request exceeded the model's context window."""
pass
class AuthError(LLMError):
"""API key is invalid or missing."""
pass
def call_llm(
messages: list,
model: str = "gpt-4o-mini",
max_retries: int = 5,
base_delay: float = 1.0,
max_delay: float = 60.0,
timeout: float = 30.0
) -> str:
"""
Robust LLM call with comprehensive error handling.
Raises:
AuthError: API key is invalid (do not retry, escalate)
ContentFilterError: Request blocked by content filter
ContextLengthError: Request exceeds model context window
LLMError: Other non-retryable errors
RateLimitError: After exhausting retries
InternalServerError: After exhausting retries
"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=2048,
timeout=timeout
)
return response.choices[0].message.content
except AuthenticationError as e:
# API key is wrong — do not retry, alert immediately
logger.critical(f"Authentication failed: {e}. Check OPENAI_API_KEY.")
raise AuthError("Invalid API key — check your OPENAI_API_KEY") from e
except BadRequestError as e:
error_body = str(e)
# Context length exceeded
if "context_length_exceeded" in error_body or "maximum context length" in error_body:
logger.warning(f"Context length exceeded. Messages: {len(messages)}")
raise ContextLengthError(
f"Request exceeds model context window: {error_body}"
) from e
# Content filter / moderation
elif "content_filter" in error_body or "content_policy" in error_body:
logger.warning(f"Request blocked by content filter: {error_body}")
raise ContentFilterError(
"Request was blocked by content safety filter"
) from e
else:
# Generic bad request — fix the request, do not retry
logger.error(f"Bad request (400): {error_body}")
raise LLMError(f"Bad request: {error_body}") from e
except RateLimitError as e:
if attempt == max_retries - 1:
logger.error(f"Rate limit exceeded after {max_retries} retries")
raise
delay = _backoff_with_jitter(attempt, base_delay, max_delay)
logger.warning(f"Rate limited (attempt {attempt + 1}). Retrying in {delay:.1f}s")
time.sleep(delay)
except (APITimeoutError, APIConnectionError) as e:
if attempt == max_retries - 1:
logger.error(f"Connection/timeout error after {max_retries} retries: {e}")
raise LLMError(f"API connection failed: {e}") from e
delay = _backoff_with_jitter(attempt, base_delay, max_delay)
logger.warning(f"Timeout/connection error (attempt {attempt + 1}). Retrying in {delay:.1f}s")
time.sleep(delay)
except InternalServerError as e:
if attempt == max_retries - 1:
logger.error(f"Provider server error after {max_retries} retries: {e}")
raise
delay = _backoff_with_jitter(attempt, base_delay * 2, max_delay) # Longer wait for 5xx
logger.warning(f"Server error 5xx (attempt {attempt + 1}). Retrying in {delay:.1f}s")
time.sleep(delay)
raise LLMError("Max retries exceeded")
def _backoff_with_jitter(attempt: int, base: float, maximum: float) -> float:
"""Exponential backoff with ±25% jitter to prevent thundering herd."""
delay = min(base * (2 ** attempt), maximum)
jitter = delay * 0.25 * (random.random() * 2 - 1)
return max(0.1, delay + jitter)Handling Context Length Exceeded
import tiktoken
def truncate_to_fit(
messages: list,
model: str = "gpt-4o-mini",
max_input_tokens: int = None,
reserve_output_tokens: int = 2048
) -> list:
"""
Truncate conversation history to fit within the model's context window.
Strategy: keep system prompt + truncate from the middle of history.
"""
# Context limits per model
context_limits = {
"gpt-4o": 128_000,
"gpt-4o-mini": 128_000,
"gpt-4": 8_192,
"gpt-3.5-turbo": 16_385,
}
context_limit = context_limits.get(model, 128_000)
if max_input_tokens is None:
max_input_tokens = context_limit - reserve_output_tokens
encoding = tiktoken.encoding_for_model(model)
def count_tokens(msgs: list) -> int:
total = 0
for msg in msgs:
total += 4 # per-message overhead
content = msg.get("content", "")
if isinstance(content, str):
total += len(encoding.encode(content))
elif isinstance(content, list):
for part in content:
if isinstance(part, dict) and "text" in part:
total += len(encoding.encode(part["text"]))
return total + 2 # reply priming
if count_tokens(messages) <= max_input_tokens:
return messages # Already within limit
# Separate system messages from conversation
system_messages = [m for m in messages if m.get("role") == "system"]
conversation = [m for m in messages if m.get("role") != "system"]
# Always include the most recent user message
if not conversation:
return system_messages
last_user_msg = [conversation[-1]] # Preserve the last message always
# Build from end, adding messages until we hit the limit
included = last_user_msg[:]
for msg in reversed(conversation[:-1]):
candidate = [msg] + included
if count_tokens(system_messages + candidate) <= max_input_tokens:
included = candidate
else:
break
result = system_messages + included
dropped = len(conversation) - len(included)
if dropped > 0:
logger.info(f"Truncated {dropped} messages to fit context window")
return result
def call_with_context_handling(messages: list, model: str = "gpt-4o-mini") -> str:
"""Call LLM with automatic context truncation on context length error."""
try:
return call_llm(messages, model=model)
except ContextLengthError:
logger.warning("Context too long — truncating and retrying")
truncated = truncate_to_fit(messages, model=model)
return call_llm(truncated, model=model)Content Filter Handling
def call_with_content_filter_handling(
messages: list,
model: str = "gpt-4o-mini",
safe_fallback: str = None
) -> str:
"""
Call LLM with content filter error handling.
Returns fallback message if request is blocked by content filter.
"""
try:
return call_llm(messages, model=model)
except ContentFilterError:
if safe_fallback:
return safe_fallback
# Default safe response
return (
"I'm not able to help with that request. "
"Please try rephrasing or contact support if you believe this is an error."
)
# Check for content filter in response (model-generated refusal)
def check_finish_reason(response) -> str:
"""Check if response was truncated or filtered."""
finish_reason = response.choices[0].finish_reason
if finish_reason == "content_filter":
raise ContentFilterError("Model response was filtered by content policy")
elif finish_reason == "length":
logger.warning("Response truncated — max_tokens limit reached")
# Return what we have — application decides if partial response is acceptable
return response.choices[0].message.contentCircuit Breaker Pattern
A circuit breaker prevents cascading failures during provider outages by stopping requests when error rates exceed a threshold.
import threading
from enum import Enum
from datetime import datetime, timedelta
class CircuitState(Enum):
CLOSED = "closed" # Normal operation — requests pass through
OPEN = "open" # Failure threshold exceeded — requests blocked
HALF_OPEN = "half_open" # Testing if provider has recovered
class CircuitBreaker:
"""
Circuit breaker for LLM API calls.
Prevents cascade failures during provider outages.
"""
def __init__(
self,
failure_threshold: int = 5, # Failures before opening circuit
success_threshold: int = 2, # Successes needed to close circuit
recovery_timeout: float = 60.0 # Seconds before trying again
):
self.failure_threshold = failure_threshold
self.success_threshold = success_threshold
self.recovery_timeout = recovery_timeout
self.state = CircuitState.CLOSED
self.failure_count = 0
self.success_count = 0
self.last_failure_time: datetime = None
self.lock = threading.Lock()
def _should_attempt(self) -> bool:
"""Determine if a request should be attempted."""
with self.lock:
if self.state == CircuitState.CLOSED:
return True
elif self.state == CircuitState.OPEN:
if (datetime.utcnow() - self.last_failure_time >
timedelta(seconds=self.recovery_timeout)):
self.state = CircuitState.HALF_OPEN
logger.info("Circuit breaker: OPEN → HALF_OPEN, testing provider")
return True
return False
elif self.state == CircuitState.HALF_OPEN:
return True
return False
def record_success(self):
with self.lock:
self.failure_count = 0
if self.state == CircuitState.HALF_OPEN:
self.success_count += 1
if self.success_count >= self.success_threshold:
self.state = CircuitState.CLOSED
self.success_count = 0
logger.info("Circuit breaker: HALF_OPEN → CLOSED, provider recovered")
def record_failure(self):
with self.lock:
self.failure_count += 1
self.last_failure_time = datetime.utcnow()
if self.state == CircuitState.HALF_OPEN:
self.state = CircuitState.OPEN
self.success_count = 0
logger.warning("Circuit breaker: HALF_OPEN → OPEN, provider still failing")
elif (self.state == CircuitState.CLOSED and
self.failure_count >= self.failure_threshold):
self.state = CircuitState.OPEN
logger.warning(
f"Circuit breaker: CLOSED → OPEN after {self.failure_count} failures"
)
def call(self, func, *args, **kwargs):
"""Execute function through circuit breaker."""
if not self._should_attempt():
raise LLMError(
f"Circuit breaker OPEN — provider unavailable. "
f"Last failure: {self.last_failure_time}"
)
try:
result = func(*args, **kwargs)
self.record_success()
return result
except (InternalServerError, APIConnectionError, APITimeoutError) as e:
self.record_failure()
raise
# Usage
openai_circuit = CircuitBreaker(failure_threshold=5, recovery_timeout=60)
def resilient_call(messages: list) -> str:
"""LLM call with circuit breaker protection."""
try:
return openai_circuit.call(call_llm, messages)
except LLMError as e:
if "Circuit breaker OPEN" in str(e):
# Fall back to alternative provider
return call_fallback_provider(messages)
raiseFallback Provider Pattern
import anthropic
anthropic_client = anthropic.Anthropic()
def call_fallback_provider(messages: list) -> str:
"""Fallback to Anthropic Claude if OpenAI is unavailable."""
# Convert OpenAI message format to Anthropic format
system = ""
anthropic_messages = []
for msg in messages:
if msg["role"] == "system":
system = msg["content"]
else:
anthropic_messages.append({
"role": msg["role"],
"content": msg["content"]
})
try:
response = anthropic_client.messages.create(
model="claude-3-haiku-20240307", # Fast, cheap fallback
max_tokens=2048,
system=system,
messages=anthropic_messages
)
logger.info("Served request from fallback provider (Anthropic)")
return response.content[0].text
except Exception as e:
logger.error(f"Fallback provider also failed: {e}")
raise LLMError("Both primary and fallback providers unavailable") from eStructured Error Logging
import json
from datetime import datetime
def log_api_error(
error: Exception,
messages: list,
model: str,
attempt: int,
context: dict = None
):
"""Structured error logging for LLM API failures."""
# Safely extract message preview (avoid logging full content in production)
message_preview = []
for msg in messages[-3:]: # Last 3 messages only
preview = str(msg.get("content", ""))[:100]
message_preview.append({"role": msg.get("role"), "preview": preview})
error_record = {
"timestamp": datetime.utcnow().isoformat(),
"error_type": type(error).__name__,
"error_message": str(error)[:500],
"model": model,
"attempt": attempt,
"message_count": len(messages),
"recent_messages": message_preview,
"context": context or {}
}
logger.error(f"LLM_API_ERROR: {json.dumps(error_record)}")
# In production: send to your monitoring system (Datadog, Sentry, etc.)Best Practices
Categorize errors before retrying. Not all errors benefit from retry. Auth errors (401), bad requests (400 with malformed schema), and content policy violations are not retryable without fixing the underlying issue. Only 429 and 5xx errors should trigger automatic retry.
Log errors with context but protect user data. Your error logs should include: model name, error type, HTTP status, attempt number, and message count. They should NOT include the full message content in most applications — it may contain user PII. Log previews or hashes, not full content.
Implement provider health monitoring. Track error rates per provider over a rolling 5-minute window. If a provider's error rate exceeds 20%, activate circuit breaking and route to the fallback provider before users start seeing failures.
Test error handling explicitly. Write tests that simulate 429 responses, 500 errors, and context length exceptions. Mock the API client to return specific errors and verify your handling code produces the expected behavior. This is often skipped and results in untested error paths.
Set appropriate retry budgets. Retry with a maximum total time budget, not just a maximum number of attempts. A retry that waits 1 + 2 + 4 + 8 = 15 seconds is acceptable for a background task. The same retry budget applied to a user-facing request will frustrate users. Tune differently based on the request type.
Common Mistakes
Retrying 400 Bad Request errors. A malformed request will fail on every retry. Check for 400 status codes and raise immediately rather than retrying — it wastes time and burns through retry budget.
Not distinguishing context length from other 400 errors. Context length exceeded is a 400 error like any other bad request, but it has a specific recovery action (truncate and retry) that other 400 errors do not. Check the error message body, not just the status code.
Swallowing content filter errors silently. If a user's legitimate query is blocked by a content filter, they need to know — so they can rephrase or contact support. Silently returning a generic error message without logging the filtered content makes debugging impossible.
Not implementing circuit breaking for provider outages. Without a circuit breaker, a 10-minute provider outage causes every incoming request to time out or fail after multiple retries, each consuming significant time. A circuit breaker stops the bleeding quickly.
Using the same timeout for user-facing and background requests. A 30-second timeout is fine for background processing. For a user-facing chat endpoint, consider a 15-second timeout with a clear "still working" UI indicator, or stream the response to prevent the wait.
Key Takeaways
- LLM API errors divide into four categories: client errors (400/401/422 — fix the request), rate limits (429 — retry with backoff), context errors (400 — truncate or modify), and server errors (500/503 — retry with backoff).
- Only 429 and 5xx errors are reliably retryable — 400 Bad Request errors will fail on every retry; always check the status code before deciding to retry.
- Context length exceeded and content filter errors are both 400 errors but require different recovery strategies: truncation for context length, safe fallback message for content filters.
- Exponential backoff with jitter is essential — without jitter, all instances retry simultaneously and create a thundering herd that triggers another round of rate limits.
- A circuit breaker prevents cascading failures during provider outages by stopping all requests after a failure threshold is reached and routing to a fallback provider.
- Log errors with model name, error type, HTTP status, and attempt number — but do not log full message content in production where it may contain user PII.
- Set different retry budgets for user-facing requests (short, 10–15 seconds total) vs background jobs (generous, up to several minutes).
- Implementing a fallback provider adds complexity but is worth the investment for revenue-critical applications with SLA commitments; it is not necessary for internal tools.
FAQ
What is the difference between a 429 and a 503?
A 429 (Too Many Requests) means you exceeded your rate limit — the provider's service is up, but you have consumed your allowed quota. A 503 (Service Unavailable) means the provider's service itself is temporarily unavailable. Both are retryable, but 503 indicates a provider-side issue and warrants activating your circuit breaker if it persists.
How do I tell if a content filter blocked the request vs the model refusing to answer?
A content filter block on the input returns a 400 error with content_filter in the error body before any generation occurs. A model refusal returns a 200 status with a generated text response — the model decided to decline. Check finish_reason == "content_filter" for output-side filtering.
How long should I wait before retrying a rate-limited request?
Minimum: honor the Retry-After response header if present. Without it, use exponential backoff starting at 1 second. For TPM limits (most common), the limit resets every 60 seconds — so a maximum wait of 70 seconds covers the full reset window. Add jitter to prevent synchronized retries.
Should I implement fallback providers for all applications?
Not necessarily. Fallback providers add complexity — maintaining API keys and client code for multiple providers, normalizing their response formats, and testing both paths. It is worth the investment for revenue-critical, user-facing applications with SLA commitments. For internal tools or low-stakes applications, a clear error message is often sufficient.
How do I monitor error rates in production?
Emit structured log events with error type, provider, model, and status code on every error. Set up alerts when: error rate exceeds 5% over a 5-minute window, or a specific error type (like 429) exceeds a threshold. Most observability platforms (Datadog, Grafana, Sentry) can build these dashboards from structured logs.
When should the circuit breaker open?
Open the circuit after 5 consecutive failures or when error rate exceeds 20% over a rolling 5-minute window. Recovery timeout of 60 seconds is a reasonable starting point — the circuit moves to HALF_OPEN and tests with one request. If that request succeeds, close the circuit; if it fails, reopen for another 60 seconds.
How do I distinguish AuthenticationError from a temporary API issue?
AuthenticationError (401) is deterministic — your API key is invalid, expired, or missing permissions. It will not resolve on retry. Raise it immediately, log it as critical, and alert on-call. Temporary API issues manifest as 500/503 errors, not 401s. A 401 always requires a human to investigate and fix the key.