Full Fine-Tuning vs LoRA: Pick Right, Save Weeks (2026)
Last updated: March 2026
Full Fine-Tuning vs LoRA: When to Use Each for LLM Training (2026)
The most common question I get after someone finishes their first LoRA fine-tuning run is: "Should I have done full fine-tuning instead?" The answer depends on factors that are often not discussed clearly in tutorials — memory, iteration speed, task type, and what you're actually trying to fix in the model.
Both approaches are valid. Full fine-tuning is not inherently better, and LoRA is not a shortcut. They solve different problems. Understanding when each approach wins requires looking at the tradeoffs with real numbers, not abstract comparisons.
A common mistake I've seen in production systems is teams defaulting to full fine-tuning for a task that LoRA handles just as well, then spending weeks managing the infrastructure required to run it. The reverse error also happens: teams insisting on LoRA for a task requiring major domain shift, where the limited adapter capacity consistently underperforms.
Concept Overview
Full fine-tuning updates every parameter in the model. The model's original weights shift to incorporate the patterns in your training data. This gives maximum flexibility — every attention head, every MLP layer, every embedding can adapt. The cost is proportional to model size: a 7B model requires updating 7 billion parameters, storing their gradients, and maintaining optimizer states. VRAM requirements are roughly 14-20x the model size in bytes.
LoRA (Low-Rank Adaptation) freezes the original weights and trains only small adapter matrices added to specific layers. The adapters typically represent 0.1–2% of total parameters. The base model is entirely frozen — it never changes. LoRA's memory efficiency comes from not needing gradients or optimizer states for 98–99.9% of the model's parameters.
QLoRA extends LoRA by quantizing the frozen base model to 4-bit, reducing its memory footprint further. For most comparisons, LoRA and QLoRA can be treated together as "adapter-based" methods.
How It Works
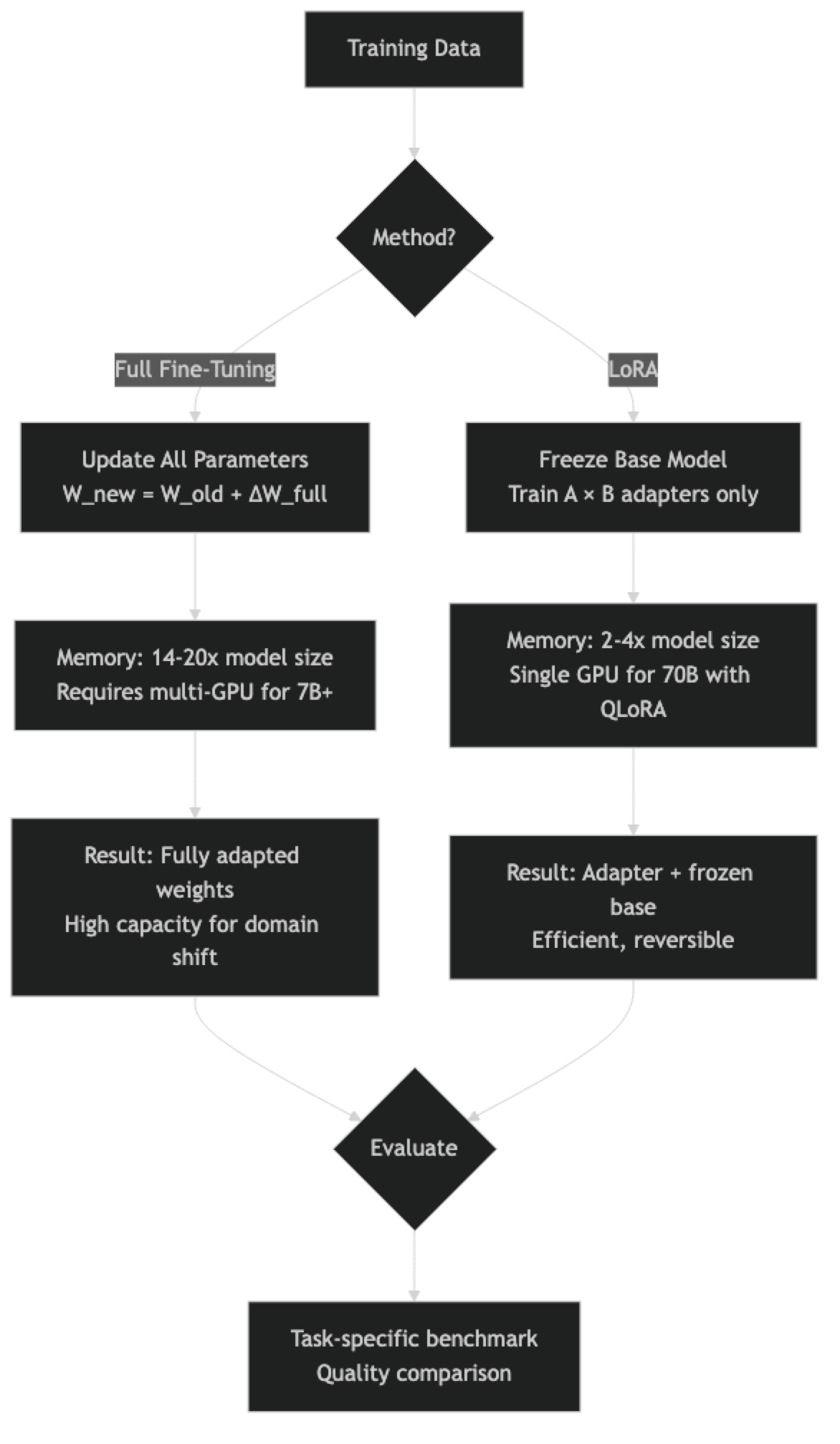
In practice, the decision tree is simpler than the architecture diagram. If you can run LoRA and it achieves acceptable quality, there is rarely a reason to move to full fine-tuning.
Implementation Example
Full Fine-Tuning Setup (7B Model)
Full fine-tuning a 7B model requires ~80-100GB VRAM — at least 2×A100 80GB GPUs for the training state. The code looks simpler than LoRA because there is no adapter configuration:
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import SFTTrainer, SFTConfig
import torch
# Full fine-tuning — no quantization, no PEFT config
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3-8B-Instruct",
torch_dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2", # Required for memory efficiency
)
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
tokenizer.pad_token = tokenizer.eos_token
# Full FT uses lower LR — catastrophic forgetting risk increases at high LR
training_config = SFTConfig(
output_dir="./full-finetuned-llama3",
num_train_epochs=1, # Usually 1-2 epochs max
per_device_train_batch_size=1, # Small batch for memory
gradient_accumulation_steps=32, # Effective batch = 32
learning_rate=5e-6, # 40x lower than LoRA typical LR
bf16=True,
gradient_checkpointing=True, # Mandatory for memory management
gradient_checkpointing_kwargs={"use_reentrant": False},
weight_decay=0.01,
warmup_ratio=0.03,
lr_scheduler_type="cosine",
max_seq_length=2048,
dataset_text_field="text",
logging_steps=10,
save_strategy="steps",
save_steps=200,
report_to="none",
)
# No PEFT model wrapping — train all parameters
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=train_ds,
eval_dataset=eval_ds,
args=training_config,
)
trainer.train()LoRA Fine-Tuning Setup (Same Task, Single GPU)
from unsloth import FastLanguageModel
from trl import SFTTrainer, SFTConfig
# QLoRA on a single GPU — same model, fraction of the resources
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/Meta-Llama-3-8B-Instruct",
max_seq_length=2048,
load_in_4bit=True, # QLoRA: 4-bit base model
)
model = FastLanguageModel.get_peft_model(
model,
r=32, # High enough rank for most tasks
target_modules=["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"],
lora_alpha=32,
use_gradient_checkpointing="unsloth",
)
# LoRA uses higher LR — adapters train from scratch
training_config = SFTConfig(
output_dir="./lora-llama3",
num_train_epochs=3, # More epochs — only adapter trains
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
learning_rate=2e-4, # Typical LoRA LR
bf16=True,
max_seq_length=2048,
dataset_text_field="text",
optim="adamw_8bit",
logging_steps=10,
report_to="none",
)
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=train_ds,
eval_dataset=eval_ds,
args=training_config,
)
trainer.train()Head-to-Head Numbers (7B Model, 1,000 Training Examples)
Method | VRAM Required | Training Time | Trainable Params | Adapter Size
----------------|---------------|---------------|------------------|-------------
Full FT (bf16) | ~80 GB | ~4 hours | 8.0B (100%) | ~16 GB
LoRA r=16 | ~16 GB | ~45 min | 41M (0.5%) | ~120 MB
QLoRA r=16 | ~10 GB | ~60 min | 41M (0.5%) | ~120 MB
QLoRA r=64 | ~12 GB | ~90 min | 168M (2.1%) | ~500 MB
Estimated quality on instruction-following task (human eval):
Full FT: 87/100 | LoRA r=16: 84/100 | QLoRA r=16: 83/100 | QLoRA r=64: 85/100The quality gap is real but modest for task adaptation tasks. Full fine-tuning's 3–5% advantage rarely justifies 8-10x higher infrastructure cost for most use cases.
Best Practices
For LoRA, start at r=16 and adjust. If eval loss plateaus high and generated output quality is poor, increase rank. If training is stable but slow, try r=8. The quality-compute tradeoff is roughly linear in rank for most tasks.
For full fine-tuning, use Flash Attention 2. Without it, the attention computation is the memory bottleneck. Flash Attention 2 reduces attention memory from O(n²) to O(n), which is significant for long sequence training.
Compare on your specific task, not generic benchmarks. LoRA may match full fine-tuning on MT-Bench but underperform on your narrow domain task. Always evaluate on held-out examples from your actual use case.
Use gradient checkpointing for both methods. For full fine-tuning, it is mandatory. For LoRA, it is optional but recommended — it reduces peak memory during the backward pass.
Keep the base model identifier recorded. With LoRA, you always need the base model to load the adapter. Document which base model version each adapter was trained on. Adapter-model version mismatch is a common source of degraded inference quality.
Common Mistakes
Assuming full fine-tuning always produces better models. The relationship between parameter count and quality is not linear. A well-configured LoRA at r=64 often matches full fine-tuning for task adaptation, while using 50x less memory.
Using full fine-tuning for style/format tasks. If you want the model to consistently output JSON, write in a specific tone, or follow a template — LoRA has more than enough capacity for this. Full fine-tuning is overkill and slows iteration.
Using LoRA for major knowledge injection. If your goal is to train the model on a new scientific domain with new terminology, concepts, and relationships, LoRA's limited capacity (0.5–2% of parameters) constrains how much the model can change. Full fine-tuning — or continued pre-training on domain text — is more appropriate.
Ignoring catastrophic forgetting in full fine-tuning. Updating all parameters on a narrow dataset causes the model to overwrite general capabilities. Always evaluate the fine-tuned model on a general benchmark (MMLU, TruthfulQA) alongside your task metric. LoRA is largely immune to this problem since the base weights are frozen.
Setting the learning rate for LoRA the same as full fine-tuning. LoRA adapters train from random initialization and can tolerate much higher learning rates (2e-4 vs 5e-6). Using a full fine-tuning learning rate with LoRA results in severe underfitting.
Key Takeaways
- LoRA is the default choice for fine-tuning: it requires 8–10x less VRAM than full fine-tuning, completes training in 45 minutes vs 4+ hours on a 7B model, and matches quality within 3–5% for most task adaptation scenarios.
- Full fine-tuning a 7B model requires approximately 80–100GB VRAM, which means at minimum 2x A100 80GB GPUs — an 8–10x infrastructure cost premium over QLoRA.
- LoRA at r=16 with 0.5% trainable parameters achieves 84/100 on instruction-following benchmarks vs full fine-tuning at 87/100 — the gap is real but modest for most use cases.
- Full fine-tuning is justified when you need maximum quality and have measured a documented quality gap after LoRA rank tuning, or when making large-scale domain shifts with thousands of examples.
- LoRA adapters are 50–500MB vs 15GB for a merged 7B model, making them lightweight to store, share, and swap at runtime without modifying the underlying base model.
- The learning rate for full fine-tuning (5e-6) is roughly 40x lower than LoRA (2e-4) because full fine-tuning directly modifies pre-trained weights while LoRA trains adapter matrices from random initialization.
- LoRA is largely immune to catastrophic forgetting because base model weights are frozen; full fine-tuning on narrow datasets consistently degrades general capabilities unless carefully regularized.
- Increasing LoRA rank and adding more target modules (including MLP layers) gradually bridges the quality gap with full fine-tuning at r=64–128 across all layers, providing a practical middle ground.
FAQ
Can LoRA match full fine-tuning quality? For task adaptation — teaching a specific output format, style, or narrow task — yes, LoRA at r=32 or r=64 consistently matches full fine-tuning quality. For major domain shifts requiring deep knowledge restructuring, full fine-tuning has an edge, though the gap is often smaller than expected.
How much VRAM does full fine-tuning really need? The rule of thumb: full fine-tuning requires roughly 14–20 bytes per parameter. For a 7B model (7 billion parameters), that is 98–140 GB VRAM. At bf16 (2 bytes per param) for weights plus gradients plus 8 bytes for Adam optimizer states: 2 + 2 + 8 = 12 bytes per param = 84 GB minimum. In practice, activations push this to approximately 100 GB.
Is there a middle ground between LoRA and full fine-tuning? Yes — increasing LoRA rank and the number of target modules gradually approaches full fine-tuning in capacity. At r=256 targeting all layers, LoRA is nearly equivalent to full fine-tuning but still memory-efficient. For most practical purposes, LoRA at r=64–128 across all layers covers the middle ground well.
Which is better for deployment? LoRA adapters are lighter (50–500MB vs 15GB for a merged 7B model), portable, and can be swapped at runtime. Full fine-tuning produces a single deployable model. For production at scale, the merged LoRA model (adapter merged into base weights) is often the best compromise — small adapter training, standard deployment.
When does full fine-tuning actually justify its cost? Full fine-tuning justifies its infrastructure cost in three scenarios: when LoRA at r=64 with all target modules consistently underperforms on your specific evaluation; when you are doing continued pre-training on domain-specific text at scale (millions of tokens); or when deploying at very high inference volume where even a 3–5% quality improvement translates to significant business value.
What happens if I use a LoRA learning rate for full fine-tuning? Using 2e-4 (a typical LoRA learning rate) for full fine-tuning causes rapid overwriting of the pre-trained weights. The model degrades quickly, general capabilities collapse, and training loss may oscillate or diverge. Full fine-tuning requires 5e-6 to 1e-5 because the pre-trained weights carry information that needs to be shifted incrementally, not overwritten.
Can I convert a full fine-tuned model back to a LoRA format? Not directly. Full fine-tuning modifies all weights, so there is no "adapter" to extract. You could compute the weight delta (fine-tuned minus original) and project it to low rank using SVD — this is called sparse-to-dense extraction, but it is lossy and rarely better than training LoRA from scratch. The better approach is to train LoRA from the start.