Few-Shot vs Zero-Shot: When Examples Help (and Hurt) (2026)
Few-Shot vs Zero-Shot Prompting Explained
You have a text classification task. You write a clear instruction, run it, and the output looks reasonable. Then you check the full test set and notice that the format is inconsistent — sometimes the model returns "Positive", sometimes "positive", sometimes "Sentiment: Positive". The task is well-defined, but the format is not controlled.
Adding two examples fixes this immediately. That is the core value of few-shot prompting: it communicates format, domain conventions, and quality expectations faster and more reliably than written instructions alone.
This post explains when to use each approach, how to write effective examples, and what the actual trade-offs are — not in theory, but in the context of building production AI features.
Concept Overview
Zero-shot prompting asks the model to complete a task using only the instruction — no examples provided. The model relies entirely on patterns learned during pretraining.
Few-shot prompting includes 2–10 input/output examples before the task. The model uses in-context learning to infer the expected format, domain conventions, and style from the examples, then applies that pattern to the new input.
The terminology comes from machine learning: "shots" are training examples. Zero-shot means no task-specific examples. Few-shot means a small number of examples in-context (not gradient updates — no fine-tuning involved).
One-shot prompting — a single example — is a special case of few-shot. It provides some format guidance with minimal token overhead.
In practice, zero-shot is your default starting point. Few-shot is the first upgrade to reach for when zero-shot outputs are inconsistent in format, too domain-generic, or fail on ambiguous inputs.
How It Works
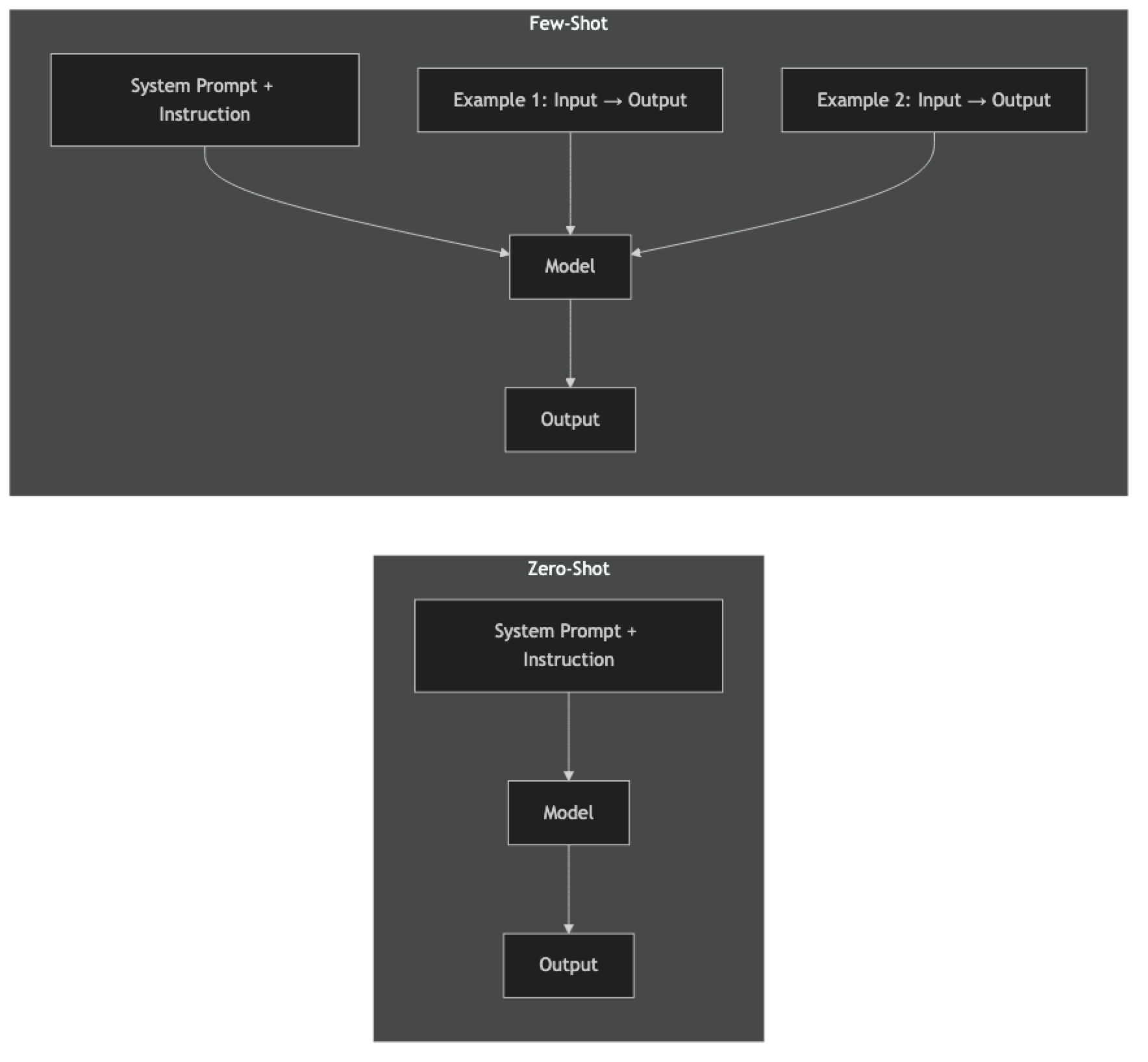
In zero-shot, the model maps the instruction directly to an output using its pretraining knowledge. In few-shot, the examples are part of the input context — the model performs in-context learning, adjusting its output distribution toward the demonstrated pattern without any weight updates.
The key mechanism: examples communicate information that is hard to express in instructions — edge cases, tone calibration, formatting nuances, and domain-specific conventions. Showing is often more efficient than telling.
Implementation Example
from openai import OpenAI
client = OpenAI()
# ─── Zero-Shot ────────────────────────────────────────────────────────────────
def zero_shot_classify(review: str) -> str:
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": "Classify the sentiment of the product review. Return ONLY one of: Positive, Negative, Mixed"
},
{"role": "user", "content": f"Review: {review}"}
],
temperature=0
)
return response.choices[0].message.content.strip()
# ─── Few-Shot ─────────────────────────────────────────────────────────────────
FEW_SHOT_EXAMPLES = [
(
"Review: The battery life is incredible — 3 days on a single charge.",
"Positive"
),
(
"Review: Absolute garbage. Broke after one week of normal use.",
"Negative"
),
(
"Review: Great camera but the software is buggy and crashes constantly.",
"Mixed"
),
(
"Review: Does exactly what it says on the box. Nothing more.",
"Positive"
),
(
"Review: Would give zero stars if I could. Complete waste of money.",
"Negative"
)
]
def few_shot_classify(review: str) -> str:
messages = [
{
"role": "system",
"content": "Classify the sentiment of product reviews. Return ONLY one of: Positive, Negative, Mixed"
}
]
# Inject examples as alternating user/assistant turns
for user_msg, label in FEW_SHOT_EXAMPLES:
messages.append({"role": "user", "content": user_msg})
messages.append({"role": "assistant", "content": label})
messages.append({"role": "user", "content": f"Review: {review}"})
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=0
)
return response.choices[0].message.content.strip()
# ─── Comparison ───────────────────────────────────────────────────────────────
test_reviews = [
"Looks premium but feels cheap. Camera is stunning though.",
"My third time buying this. Never disappoints.",
"Arrived broken. Packaging was damaged. Terrible experience.",
"Solid product. Would appreciate better documentation.",
]
print(f"{'Review':<50} {'Zero-Shot':<12} {'Few-Shot':<12}")
print("-" * 74)
for review in test_reviews:
zs = zero_shot_classify(review)
fs = few_shot_classify(review)
print(f"{review[:48]:<50} {zs:<12} {fs:<12}")Few-Shot for Structured Extraction
The real power of few-shot becomes apparent with structured extraction, where format consistency is critical:
EXTRACTION_EXAMPLES = [
(
"John will follow up with the design team by Friday.",
'{"owner": "John", "action": "follow up with design team", "due": "Friday"}'
),
(
"Sarah needs to update the onboarding docs before the sprint ends.",
'{"owner": "Sarah", "action": "update onboarding docs", "due": "end of sprint"}'
),
(
"No specific owner assigned — the backend team should investigate the timeout errors.",
'{"owner": null, "action": "investigate timeout errors", "due": null}'
)
]
def extract_action_item(line: str) -> dict:
import json
messages = [
{"role": "system", "content": "Extract action items from meeting notes. Return ONLY valid JSON with fields: owner (string|null), action (string), due (string|null)"}
]
for user_msg, assistant_msg in EXTRACTION_EXAMPLES:
messages.append({"role": "user", "content": user_msg})
messages.append({"role": "assistant", "content": assistant_msg})
messages.append({"role": "user", "content": line})
r = client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=0,
response_format={"type": "json_object"}
)
return json.loads(r.choices[0].message.content)
# Test
result = extract_action_item("The DevOps team needs to set up staging by next Wednesday.")
print(result)
# {"owner": "DevOps team", "action": "set up staging", "due": "next Wednesday"}Notice the third example with null fields — this is an intentional edge case example. Without it, the model would likely hallucinate a value for missing fields rather than returning null.
When to Use Zero-Shot
Use zero-shot when:
- The task is clear and well-defined with no ambiguous edge cases
- The output format is simple (single label, yes/no, short phrase)
- The domain is general — the model's training data covers it well
- You need to minimize token usage at scale
- You are prototyping and want to iterate quickly before adding examples
Zero-shot works reliably for: language detection, topic classification with broad categories, simple sentiment analysis, standard summarization, and factual Q&A.
When to Use Few-Shot
Use few-shot when:
- Format consistency is critical (especially for structured outputs parsed by code)
- The task has domain-specific conventions the model may not know
- You have observed inconsistent output format with zero-shot
- The categories are ambiguous and you want to calibrate which way to classify edge cases
- You need to demonstrate quality level — what "good" looks like for your use case
Few-shot is particularly valuable for: custom JSON schema extraction, classification with nuanced or overlapping categories, tone-specific writing, and domain-specific analysis (legal, medical, financial).
Writing Effective Examples
Bad examples are worse than no examples. They teach the model the wrong pattern or create inconsistent signals.
Principles for effective few-shot examples:
Cover edge cases, not just easy cases. If your classifier has a "Mixed" category, include 1–2 Mixed examples with different types of mixed content. Easy cases add tokens without adding information.
Match the quality level you want. If you want concise outputs, your examples should be concise. If you want detailed analysis, demonstrate that level of detail.
Keep the format in examples identical to what you want. The model will mimic the exact format of your examples — capitalization, punctuation, whitespace. Make sure your examples use the exact format your downstream code expects.
Include the null/empty/unknown case. Always include at least one example demonstrating what to return when a field is missing or unknown. This prevents hallucination on incomplete inputs.
Use real data. Synthetic examples that are too clean will not generalize to messy real-world inputs. Use actual examples from your data, including any formatting quirks.
Cost and Performance Trade-offs
| Zero-Shot | Few-Shot (5 examples) | |
|---|---|---|
| Input tokens | Low | Medium (adds 200–600 tokens) |
| Format consistency | Variable | High |
| Domain accuracy | Baseline | Better for niche domains |
| Edge case handling | Model default | Controlled by examples |
| Iteration speed | Fast | Slower (need to curate examples) |
At 100,000 requests/day, 400 extra tokens per request (typical few-shot overhead) costs roughly $5–8/day on GPT-4o at current pricing. For most applications, the improvement in consistency and accuracy justifies this. For very high volume, low-cost tasks, measure the actual accuracy delta before committing.
Best Practices
Start zero-shot, add few-shot based on evidence. Build a 20-example test set. If zero-shot accuracy is acceptable, ship it. If not, identify the failure pattern and add examples that address it specifically.
Order examples from simple to complex. Put clean, unambiguous examples first and edge cases later. The model's attention on earlier examples is slightly higher.
Limit to 5–6 examples. Beyond that, returns diminish and you risk overfitting the model to your specific examples rather than generalizing well. Quality beats quantity.
Use the chat message format for examples. Inject examples as alternating user / assistant turns rather than embedding them in a prose block. This is the most reliable format across different models.
Keep all examples the same format. Mixing JSON examples with plain-text examples confuses the model about what format to use. Consistency across examples is critical.
Common Mistakes
Using examples that are too similar to each other. Five examples that all look the same teach the model one pattern. Cover different input types, lengths, and edge cases.
Not including a null/unknown example. When the model has no example showing what to return for a missing field, it will invent something. Always demonstrate the empty/null case.
Assuming more examples is always better. Six diverse, high-quality examples outperform fifteen redundant examples while using fewer tokens.
Using few-shot as a substitute for a clear instruction. Examples calibrate format and edge cases — they do not replace a clear task definition. The system prompt instruction and the examples work together.
Key Takeaways
- Zero-shot is the correct starting point for every new task — add few-shot only when zero-shot evidence shows format inconsistency or accuracy gaps
- Five diverse, high-quality examples outperform fifteen redundant examples while using fewer input tokens
- Always include a null/empty/unknown example in your few-shot set — without it, the model will hallucinate values for missing fields
- Format consistency in examples is critical: capitalization, punctuation, and whitespace in examples are exactly what the model replicates in output
- The typical few-shot overhead of 200–600 extra tokens per request costs roughly $5–8 per 100,000 daily requests on GPT-4o
- Use alternating user/assistant message turns to inject examples — this is more reliable across models than embedding examples in a single prose block
- Build a 20-example labeled test set before deciding between zero-shot and few-shot; measurement beats intuition
- Zero-shot works well for general tasks (language detection, broad classification, simple summarization); few-shot excels for custom schemas, niche domains, and nuanced category boundaries
FAQ
Is few-shot the same as fine-tuning? No. Few-shot examples live in the prompt context — no model weights are updated. Fine-tuning updates the model's weights using gradient descent on a training dataset. Few-shot is inference-time; fine-tuning is training-time.
How do I know if my examples are helping or hurting? Build a test set, measure zero-shot accuracy, then measure few-shot accuracy with the same test set. If few-shot accuracy is lower, your examples are teaching the wrong pattern — revise them or add more diverse examples covering different input types.
Does the order of examples matter? Yes, slightly. The model pays more attention to examples closer to the actual query. Put the most representative examples last. Do not put your only null/edge case example first where it has the least influence.
Can I use few-shot prompting with system prompts? Yes, and this is the standard pattern. The system prompt defines the task and rules. Examples in the user/assistant turns demonstrate the format. Both together is more reliable than either alone.
What is the maximum number of few-shot examples that makes sense? For most tasks, 3–5 examples is the sweet spot. Context window limits vary by model, but token cost is usually the binding constraint before context length becomes an issue.
When should I switch from few-shot to fine-tuning? When you have hundreds of labeled examples and the same prompt runs at high volume. Fine-tuning moves examples into model weights, eliminating per-request token cost. The crossover point depends on volume and model pricing, but it is typically above 50,000 daily requests.
How do I handle edge cases my few-shot examples do not cover? Add examples specifically covering those edge cases. If you discover a class of inputs consistently fails, that is exactly the scenario your examples need to demonstrate. Real production failure patterns are the best source for new examples.
What to Learn Next
- Few-Shot Prompting Explained — deep dive into example selection strategy and anti-patterns
- Prompt Engineering Best Practices — versioning, test-driven evaluation, and production lifecycle management
- Prompt Engineering Techniques — the complete catalog of prompting methods beyond zero-shot and few-shot
- Chain-of-Thought Prompting Explained — add step-by-step reasoning for complex tasks
- System Prompts: How to Control LLM Behavior — combine role definitions with few-shot examples for maximum consistency