Embedding Models: Choose Wrong and RAG Quality Tanks (2026)
A developer benchmarked their RAG system's retrieval quality and saw 68% recall@5 — meaning 32% of the time, the correct document was not in the top 5 results. They blamed their vector database configuration, tuned HNSW parameters for a week, and moved the needle by 2 percentage points.
The real fix took 20 minutes: swap text-embedding-ada-002 (released 2022) for text-embedding-3-small (released 2024). Recall jumped from 68% to 87%. The index configuration was never the problem — the embedding model was the bottleneck.
The embedding model is the quality ceiling of any vector search system. No indexing strategy, no reranking pipeline, and no prompt engineering compensates for vectors that do not capture semantic meaning accurately. Choosing the right model for your domain and budget is the highest-leverage decision in a vector search project.
Concept Overview
Embedding models convert text into dense float vectors. Models differ along several axes that matter for production use:
Quality — measured by retrieval recall on standard benchmarks (MTEB, BEIR). Higher-quality models produce vectors where semantic similarity more reliably corresponds to geometric proximity.
Dimensions — the length of the output vector. Higher dimensions generally capture more semantic nuance but cost more memory, storage, and compute at query time.
Max tokens — the maximum input length the model accepts. Inputs exceeding the limit are silently truncated, degrading embedding quality for long documents.
Speed — embedding throughput in tokens per second. Critical for indexing large corpora and for real-time query embedding at high QPS.
Cost — API models bill per token. Self-hosted open-source models have infrastructure costs instead.
Specialization — general-purpose vs. domain-specific (code, biomedical, legal). Domain-specific models often outperform general ones on in-domain benchmarks.
How It Works
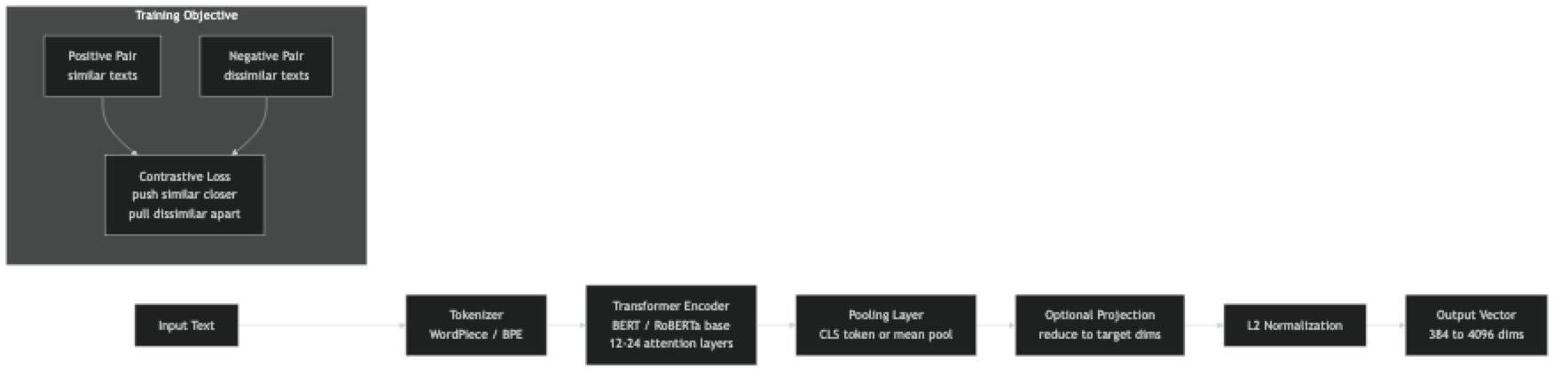
All modern text embedding models share the same basic architecture: a transformer encoder (BERT-style) with a pooling layer on top. The differences are in training data, training objective design, hard negative mining strategies, and model scale.
The key training innovation in recent models is hard negative mining — during training, negative examples are not random documents but documents that are superficially similar to the positive but semantically different. Models trained with harder negatives learn finer-grained semantic distinctions, which shows up as better recall on ambiguous queries.
Implementation Example
Benchmark Multiple Models on Your Data
pip install sentence-transformers openai cohere numpy datasetsimport numpy as np
from sentence_transformers import SentenceTransformer
from openai import OpenAI
import time
from dataclasses import dataclass
@dataclass
class ModelConfig:
name: str
dim: int
provider: str # "st" = sentence-transformers, "openai", "cohere"
model_id: str
max_tokens: int
cost_per_million: float # USD per 1M tokens, 0 = self-hosted
MODELS = [
ModelConfig("BGE-small-en", 384, "st", "BAAI/bge-small-en-v1.5", 512, 0),
ModelConfig("BGE-base-en", 768, "st", "BAAI/bge-base-en-v1.5", 512, 0),
ModelConfig("BGE-large-en", 1024,"st", "BAAI/bge-large-en-v1.5", 512, 0),
ModelConfig("E5-large", 1024,"st", "intfloat/e5-large-v2", 512, 0),
ModelConfig("MiniLM-L6", 384, "st", "sentence-transformers/all-MiniLM-L6-v2", 256, 0),
ModelConfig("OAI-3-small", 1536,"openai","text-embedding-3-small",8191, 0.02),
ModelConfig("OAI-3-large", 3072,"openai","text-embedding-3-large",8191, 0.13),
]
oai = OpenAI()
def embed_with_model(config: ModelConfig, texts: list[str]) -> np.ndarray:
if config.provider == "st":
model = SentenceTransformer(config.model_id)
# BGE and E5 require instruction prefix for queries
if "bge" in config.model_id.lower():
texts = [f"Represent this sentence for searching relevant passages: {t}" for t in texts]
elif "e5" in config.model_id.lower():
texts = [f"query: {t}" for t in texts]
return model.encode(texts, normalize_embeddings=True, batch_size=64)
elif config.provider == "openai":
response = oai.embeddings.create(model=config.model_id, input=texts)
vecs = np.array([r.embedding for r in response.data], dtype=np.float32)
return vecs / np.linalg.norm(vecs, axis=1, keepdims=True)
raise ValueError(f"Unknown provider: {config.provider}")
def measure_recall_at_k(
model_config: ModelConfig,
queries: list[str],
corpus: list[str],
relevant_ids: list[int], # correct document index for each query
k: int = 5,
) -> dict:
start = time.time()
corpus_embs = embed_with_model(model_config, corpus)
index_time = time.time() - start
hits = 0
total_query_time = 0.0
for query, correct_id in zip(queries, relevant_ids):
start = time.time()
q_emb = embed_with_model(model_config, [query])[0]
q_time = time.time() - start
total_query_time += q_time
scores = corpus_embs @ q_emb
top_k = np.argsort(scores)[::-1][:k]
if correct_id in top_k:
hits += 1
return {
"model": model_config.name,
"recall_at_k": hits / len(queries),
"dims": model_config.dim,
"index_time_s": index_time,
"avg_query_ms": total_query_time / len(queries) * 1000,
"cost_per_million_tokens": model_config.cost_per_million,
}
# Sample benchmark dataset
queries = [
"How do vector databases handle approximate nearest neighbor search?",
"What is the difference between cosine and euclidean distance for embeddings?",
"How do I reduce the memory footprint of a vector index?",
"What is product quantization in the context of FAISS?",
"How does HNSW graph construction work?",
]
corpus = [
"HNSW builds a multi-layer navigable graph where each node connects to M nearest neighbors",
"Cosine similarity measures the angle between vectors; euclidean distance measures straight-line distance",
"Product quantization compresses vectors by splitting them into subvectors and quantizing each",
"IVF partitions the vector space into Voronoi cells and searches only the nearest clusters",
"Scalar quantization maps float32 values to int8, reducing memory by 4x with minimal recall loss",
"HNSW efConstruction controls how thoroughly the graph is built; higher values give better recall",
"Vector databases like Qdrant, Pinecone, and ChromaDB support HNSW indexing natively",
]
relevant_ids = [0, 1, 5, 2, 0] # correct document index for each query
# Run benchmark on local models only (no API keys needed)
local_models = [m for m in MODELS if m.provider == "st"]
for config in local_models:
result = measure_recall_at_k(config, queries, corpus, relevant_ids, k=3)
print(f"{result['model']:20s} recall@3={result['recall_at_k']:.2f} "
f"dims={result['dims']:4d} query={result['avg_query_ms']:.1f}ms")Using BGE Models Correctly (with Instruction Prefix)
BGE and E5 models were trained with asymmetric prompts. Not using them degrades quality by 5–15%.
from sentence_transformers import SentenceTransformer
import numpy as np
model = SentenceTransformer("BAAI/bge-base-en-v1.5")
def embed_query(text: str) -> np.ndarray:
"""Queries need the instruction prefix for BGE models."""
prefixed = f"Represent this sentence for searching relevant passages: {text}"
return model.encode([prefixed], normalize_embeddings=True)[0]
def embed_passages(texts: list[str]) -> np.ndarray:
"""Passages/documents do NOT use the prefix — they are indexed as-is."""
return model.encode(texts, normalize_embeddings=True, batch_size=64)
# Index documents
passages = [
"HNSW builds a navigable small world graph for approximate nearest neighbor search",
"Product quantization compresses embedding vectors to reduce memory usage",
"Cosine similarity is the standard distance metric for text embeddings",
]
passage_embeddings = embed_passages(passages)
# Search
query = "How does approximate nearest neighbor search work?"
q_emb = embed_query(query)
scores = passage_embeddings @ q_emb
for score, passage in sorted(zip(scores, passages), reverse=True):
print(f"[{score:.3f}] {passage}")OpenAI Matryoshka Embeddings — Variable Dimensions
from openai import OpenAI
import numpy as np
client = OpenAI()
def embed_truncated(text: str, dimensions: int) -> np.ndarray:
"""text-embedding-3 models support Matryoshka truncation."""
response = client.embeddings.create(
model="text-embedding-3-small",
input=text,
dimensions=dimensions, # truncate to this many dims
)
vec = np.array(response.data[0].embedding, dtype=np.float32)
return vec / np.linalg.norm(vec)
# Compare storage and rough quality tradeoff
for dims in [256, 512, 1024, 1536]:
vec = embed_truncated("machine learning model training cost", dims)
storage_kb = dims * 4 / 1024
print(f"dims={dims:4d} storage={storage_kb:.1f}KB/vector")Best Practices
Evaluate on your own data, not MTEB benchmarks alone. MTEB measures retrieval on standard web-crawl datasets. If your domain is legal contracts, biomedical literature, or Python code, the MTEB ranking may not reflect real-world performance on your queries. Run a 50–100 query evaluation with labeled relevant documents before committing to a model.
Use BGE or E5 instruction prefixes exactly as documented. Missing the query prefix for BGE models is the single most common mistake that leads to poor retrieval quality in production. The model was trained with these prefixes — without them, you get a different vector space than the one the model learned.
Prefer smaller models that fit your quality bar over larger models by default. bge-small-en-v1.5 (33M params, 384 dims) handles most English retrieval tasks within 5% of bge-large-en-v1.5 (335M params, 1024 dims) while being 10x faster at indexing time. Start small, measure, and upgrade only if needed.
For code search, use a code-specialized embedding model. General text embedding models were trained on web text. They do not handle syntax, method names, or API signatures reliably. microsoft/codebert-base or Salesforce/codet5p-110m-embedding give significantly better recall on code-specific queries.
Cache embeddings by content hash, not by index position. When you update a document, you only need to re-embed that document, not the entire corpus. Content-addressed caching lets you incrementally update your embedding store.
Common Mistakes
Still using text-embedding-ada-002 in production. OpenAI discontinued active development of ada-002. text-embedding-3-small achieves better quality at lower cost per token. There is no justification for new systems to use ada-002.
Not specifying dimensions for OpenAI 3-series models when cost is a concern. text-embedding-3-small defaults to 1536 dims but supports truncation to 256 dims via the dimensions parameter. At 256 dims, storage and compute are 6x cheaper with ~10% quality loss — often an acceptable trade for bulk processing.
Mixing embedding models within one index. If you index 1M documents with model A, then update model A (or switch to model B) for new documents, the vectors are in different geometric spaces. Similarity scores between old and new vectors are meaningless. You must reindex everything when changing the embedding model.
Using average pooling without normalization. Some sentence transformer implementations return un-normalized pooled embeddings. If you compute dot product instead of cosine similarity on un-normalized vectors, magnitude differences dominate — longer documents get systematically higher scores regardless of relevance.
Not evaluating multilingual models on low-resource languages. Most multilingual benchmarks weight English and Western European languages heavily. If you need good coverage for Hindi, Swahili, or Vietnamese, test explicitly — models with strong MTEB multilingual scores often drop significantly on low-resource languages.
Key Takeaways
- The embedding model is the quality ceiling of your vector search system — index configuration changes rarely move recall more than 2–3 percentage points compared to a model upgrade
- BGE and E5 models require asymmetric instruction prefixes for queries ("Represent this sentence for searching relevant passages:") — omitting them degrades retrieval by 5–15%
text-embedding-3-smalloutperforms the oldertext-embedding-ada-002at lower cost — there is no reason to use ada-002 for new systems- Matryoshka Representation Learning in OpenAI 3-series models lets you truncate to any lower dimension (256, 512, 1024) and retain most quality
- MTEB scores are a useful first filter but do not replace evaluation on your specific domain and query distribution
- Content-hash-based embedding caching lets you incrementally update your corpus without re-embedding unchanged documents
- For code search, use a code-specialized model (
codebert-base,codet5p-110m-embedding) — general text models perform poorly on syntax and API names - Start with
bge-small-en-v1.5(free, fast) ortext-embedding-3-small(managed, excellent quality) and upgrade only after measuring a quality gap
FAQ
What is MTEB and should I use it to choose an embedding model? MTEB (Massive Text Embedding Benchmark) is the standard benchmark for embedding model quality across retrieval, classification, clustering, and other tasks. It is useful as a first filter but does not replace evaluation on your own data. Domain-specific models often outperform general-purpose models on specific domains even when ranked lower on MTEB overall.
Is text-embedding-3-large worth the 6.5x higher cost vs. text-embedding-3-small?
For most applications, no. text-embedding-3-small achieves 90–95% of text-embedding-3-large's performance on standard retrieval benchmarks. The meaningful difference shows up in nuanced domain-specific queries and multi-step reasoning tasks. Benchmark both on your specific use case before committing to the larger model.
Can I fine-tune OpenAI embedding models?
As of 2026, OpenAI does not support fine-tuning of their embedding models (unlike their completion models). For domain-specific fine-tuning, use open-source models (BGE, E5, MiniLM) with the sentence-transformers fit() API.
What is Matryoshka Representation Learning (MRL)?
MRL trains embedding models so that the first N dimensions of the output are themselves a meaningful lower-dimensional embedding. OpenAI's text-embedding-3 models use MRL, allowing you to truncate to any dimension (256, 512, 1024, 1536) and still get a usable embedding. This is useful for tiered storage or when you want to trade storage cost for quality.
Which embedding model works best for multilingual RAG?
intfloat/multilingual-e5-large and Cohere's embed-multilingual-v3.0 are the strongest open-source and managed options respectively as of 2026. Both support 100+ languages and maintain reasonable quality on cross-lingual retrieval (query in one language, documents in another).
How do I know when to upgrade my embedding model? Upgrade when: your recall@K on your golden test set is below 80%, you have switched domains significantly (general to legal/medical/code), or a new model version offers >5% improvement on a benchmark relevant to your use case. Do not upgrade without re-benchmarking on your own data first.
What is hard negative mining and why does it matter? Hard negative mining is a training technique where negative examples are not random documents but documents that are superficially similar to the positive example. Models trained with harder negatives learn finer-grained semantic distinctions — this is the main reason recent models (BGE, E5, Cohere 3) significantly outperform older models like ada-002.