Chain-of-Thought Prompting: Fix LLM Logic Failures (2026)
Chain-of-Thought Prompting Explained for Developers
A support team I worked with had built a pricing calculator in GPT-4 that returned wrong numbers intermittently. The calculations were not complex — multi-tier pricing with a discount rule — but the model would occasionally skip a step and arrive at a plausible-looking wrong answer. Adding "Think step by step" to the prompt eliminated almost all of these errors in one change.
That is chain-of-thought (CoT) prompting in a sentence: guiding the model to generate intermediate reasoning before committing to a final answer. It is one of the highest-value techniques in production prompt engineering, particularly for any task that involves multi-step logic.
This post explains how CoT works, when to use it, and how to implement it effectively — including zero-shot CoT, few-shot CoT, self-consistency, and Tree of Thought.
Concept Overview
Chain-of-thought prompting works by instructing the model to show its reasoning process before producing a final answer. Instead of mapping directly from input to output, the model generates a chain of intermediate steps — like showing work in a math exam.
The mechanism: language models predict one token at a time. When the model generates reasoning tokens before the answer, those tokens become part of the context for the final answer. Better context produces better predictions. The model effectively conditions its answer on a correct (or approximately correct) reasoning chain.
Without CoT:
Q: A store sells 3 shirts for $45. How much do 7 shirts cost?
A: $95With CoT:
Q: A store sells 3 shirts for $45. How much do 7 shirts cost? Think step by step.
A: First, find the cost per shirt: $45 ÷ 3 = $15 per shirt.
Then multiply by 7: $15 × 7 = $105.
The answer is $105.CoT does not teach the model new facts or capabilities. It surfaces reasoning capabilities that are already present in larger models but not activated by direct answer prompting. This is why CoT has minimal effect on small models (< 7B parameters) — the reasoning capability must already exist.
How It Works
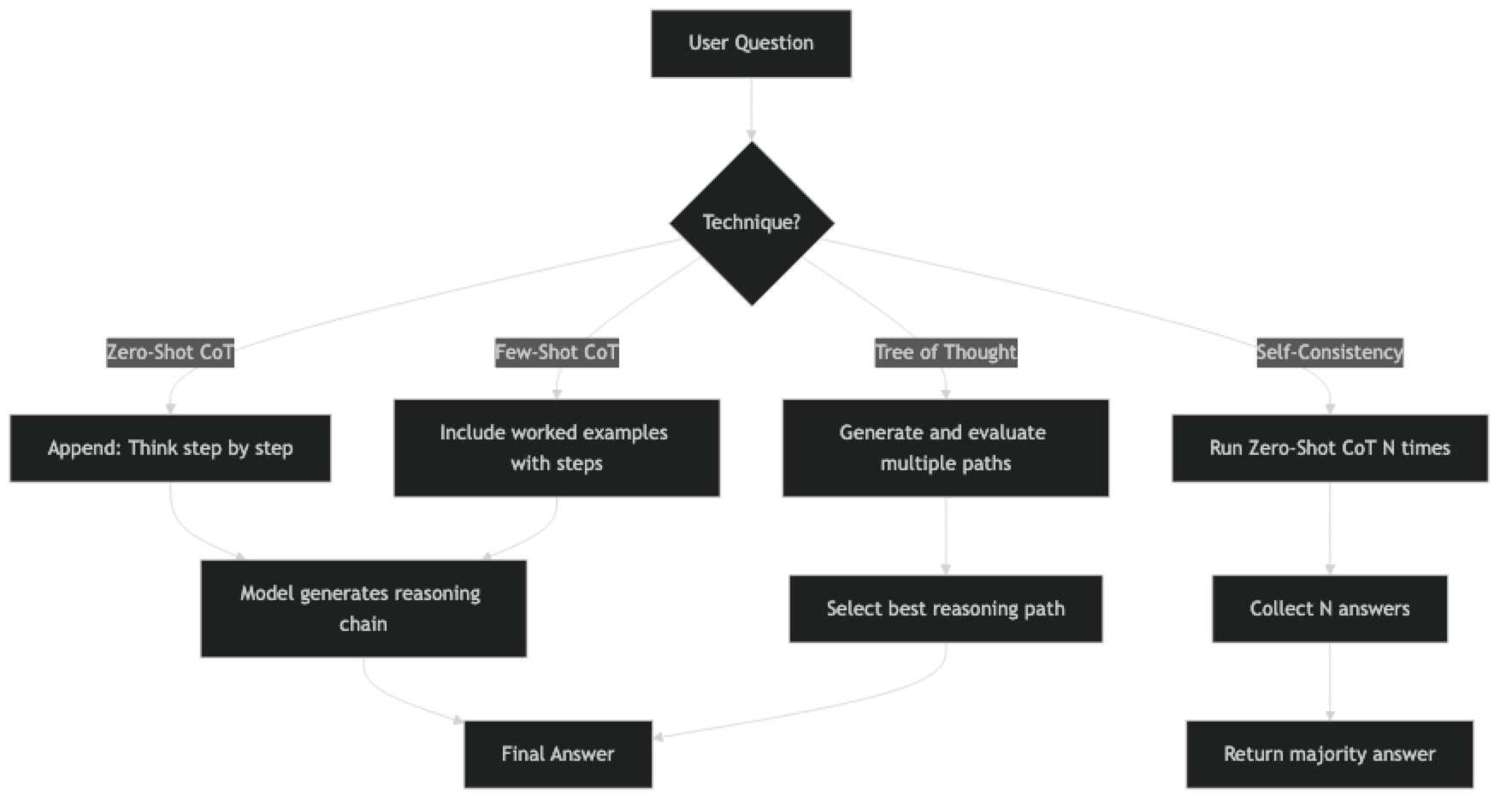
Implementation Example
Technique 1: Zero-Shot CoT
The simplest form — append a trigger phrase to any question:
from openai import OpenAI
client = OpenAI()
def zero_shot_cot(question: str) -> str:
"""Add step-by-step reasoning with a single trigger phrase."""
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": "You are a careful reasoning assistant. Think through problems step by step before answering."
},
{
"role": "user",
"content": f"{question}\n\nLet's think step by step."
}
],
temperature=0
)
return response.choices[0].message.content
# Test on different task types
print(zero_shot_cot(
"A train leaves at 2:15 PM traveling 75 mph. Another train leaves the same station "
"at 3:00 PM traveling 90 mph. When does the second train catch the first?"
))
print(zero_shot_cot(
"A Python list is [3, 1, 4, 1, 5, 9, 2, 6]. "
"What does sorted(set(lst))[-2] return?"
))Effective trigger phrases for zero-shot CoT:
- "Let's think step by step."
- "Think through this carefully before answering."
- "Work through this step by step."
- "First, let me identify what we know..."
- "Step 1:"
Technique 2: Few-Shot CoT
Provide worked examples that demonstrate the reasoning pattern:
FEW_SHOT_COT_SYSTEM = """Solve problems step by step. Show every calculation.
End with a clear final answer on its own line."""
FEW_SHOT_EXAMPLES = [
(
"Tom has 3 times as many marbles as Jerry. Together they have 48. How many does Tom have?",
"""Let Jerry have x marbles. Then Tom has 3x.
Together: x + 3x = 4x = 48
x = 12 (Jerry's marbles)
Tom has 3 × 12 = 36 marbles.
Final answer: 36"""
),
(
"A recipe uses 2.5 cups of flour for 12 cookies. How much flour for 30 cookies?",
"""Flour per cookie = 2.5 ÷ 12 = 0.2083 cups
For 30 cookies: 30 × 0.2083 = 6.25 cups
Final answer: 6.25 cups"""
)
]
def few_shot_cot(question: str) -> str:
messages = [{"role": "system", "content": FEW_SHOT_COT_SYSTEM}]
for user_msg, assistant_msg in FEW_SHOT_EXAMPLES:
messages.append({"role": "user", "content": user_msg})
messages.append({"role": "assistant", "content": assistant_msg})
messages.append({"role": "user", "content": question})
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=0
)
return response.choices[0].message.content
print(few_shot_cot(
"A car dealership sold 40% of its inventory in March and 25% of what remained in April. "
"If it started with 200 cars, how many remain?"
))Technique 3: Self-Consistency
Run the same CoT prompt multiple times and take the majority answer. Significantly improves accuracy for math and logic:
import re
from collections import Counter
def self_consistent_answer(question: str, n_samples: int = 5) -> dict:
"""
Generate n reasoning paths and return the majority answer.
Use temperature > 0 to get diverse reasoning paths.
"""
answers = []
for i in range(n_samples):
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": "Solve step by step. Always end with exactly: 'Final answer: [value]'"
},
{"role": "user", "content": question}
],
temperature=0.7 # Non-zero for diverse reasoning paths
)
text = response.choices[0].message.content
# Extract final answer
match = re.search(r'[Ff]inal answer[:\s]+(.+?)(?:\n|$)', text)
if match:
answers.append(match.group(1).strip())
if not answers:
return {"answer": "Could not extract answer", "confidence": 0}
counter = Counter(answers)
majority_answer, count = counter.most_common(1)[0]
return {
"answer": majority_answer,
"confidence": count / n_samples,
"all_answers": dict(counter)
}
result = self_consistent_answer(
"A store offers 15% off, then an additional 10% off the sale price. "
"What is the effective discount on a $200 item?"
)
print(f"Answer: {result['answer']} (confidence: {result['confidence']:.0%})")
print(f"All answers: {result['all_answers']}")Technique 4: Step-Back Prompting
For complex questions, first retrieve background knowledge, then answer the specific question:
def step_back_cot(specific_question: str) -> str:
"""
Two-step: first answer a general background question, then use
that background to answer the specific question.
"""
# Step 1: Generate a step-back question
step_back_q = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": "Generate a more general question that provides the background knowledge needed to answer the specific question."
},
{
"role": "user",
"content": f"Specific question: {specific_question}\n\nGeneral background question:"
}
],
temperature=0
).choices[0].message.content
# Step 2: Answer the general question
background = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": step_back_q}],
temperature=0
).choices[0].message.content
# Step 3: Answer the specific question using background knowledge
final = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": f"Use the following background knowledge to answer the specific question:\n\n{background}"
},
{"role": "user", "content": specific_question}
],
temperature=0
).choices[0].message.content
return final
# This works better than direct CoT for deep "why" questions
print(step_back_cot("Why does increasing batch size in training sometimes hurt generalization?"))Best Practices
Use CoT selectively. It adds tokens and latency. For classification, extraction, or simple factual questions, CoT often adds overhead without benefit. Reserve it for multi-step reasoning, math, logic, and complex analysis.
Combine CoT with structured output. For tasks where you need both reasoning and a parseable final answer, separate the scratchpad from the answer:
COT_WITH_OUTPUT_SYSTEM = """Think through the problem step by step in a <reasoning> block.
Then provide your final answer in a <answer> block.
Format:
<reasoning>
[step-by-step analysis]
</reasoning>
<answer>
[final answer only]
</answer>"""Use self-consistency for high-stakes decisions. When accuracy on a single question matters more than latency or cost, 5-sample self-consistency provides meaningful accuracy gains over single-sample CoT.
Test whether CoT actually helps. Build a test set. Compare accuracy with and without CoT. For modern frontier models like GPT-4o, zero-shot accuracy on many tasks is already very high, and CoT may not add significant value.
Temperature 0 for reproducibility, > 0 for self-consistency. When running a single CoT call, use temperature 0 for deterministic results. When running self-consistency (multiple samples), use 0.5–0.7 to get diverse reasoning paths.
Common Mistakes
Adding CoT to tasks that don't need it. "What is the capital of France? Let's think step by step." The reasoning overhead does not improve the answer. CoT helps when intermediate steps are genuinely necessary to arrive at the correct answer.
Using CoT on small models. CoT requires the model to have latent reasoning capability to surface. Models smaller than 7B parameters generally don't benefit significantly and may produce low-quality reasoning chains that actually confuse subsequent tokens.
Not specifying the final answer format. CoT generates verbose reasoning. If your code parses the output, you need to specify exactly how the final answer should be formatted and delimited. Use tags or a "Final answer:" prefix consistently.
Using temperature 0 for self-consistency. Self-consistency requires diverse reasoning paths to be useful. At temperature 0, all samples produce identical output. Use 0.5–0.7 to get the variance you need.
Treating CoT output as always correct. CoT reduces errors — it does not eliminate them. Models can produce plausible-looking but wrong reasoning chains. Self-consistency and explicit verification steps help catch these.
When to Use Which Technique
| Technique | Best For | Extra Cost | Latency |
|---|---|---|---|
| Zero-Shot CoT | Quick reasoning improvement, general use | ~1.5× tokens | Low |
| Few-Shot CoT | Domain-specific reasoning, consistent problem types | ~2–3× tokens | Low |
| Self-Consistency | High-accuracy math, critical decisions | 5× API calls | High |
| Step-Back | Complex "why" questions, concept-heavy problems | 3× API calls | Medium |
| Tree of Thought | Creative planning, exploratory problems | 10–20× API calls | Very High |
Key Takeaways
- Chain-of-thought (CoT) guides the model to generate intermediate reasoning before committing to a final answer — dramatically reduces errors on multi-step math, logic, and code analysis
- Zero-shot CoT ("Let us think step by step") is the right default — try it before adding worked examples
- Few-shot CoT provides complete worked reasoning chains as examples — better than zero-shot CoT for domain-specific or unusual reasoning patterns
- Self-consistency runs CoT multiple times and majority-votes the final answer — most accurate but 3-5x more expensive; use for high-stakes tasks
- CoT hurts on simple tasks — adds tokens, latency, and occasional overthinking without improving accuracy; measure before applying
- Control verbosity: add "Reason concisely in at most 100 words, then answer" to prevent runaway chains
- Zero-shot CoT is the default; Few-shot CoT when patterns are consistent; Self-consistency when accuracy justifies cost; Tree of Thought only for exploratory problems
FAQ
Does chain-of-thought work with GPT-4o mini? Yes, but with reduced effect compared to the full GPT-4o. Smaller models have less latent reasoning capability to surface. For budget-sensitive applications, test CoT with your specific task on both models to see if the accuracy gap justifies the cost difference.
Is CoT always worth the extra tokens? No. For simple classification, factual lookups, and extraction tasks, CoT adds cost without significant accuracy improvement. The decision should be data-driven: measure accuracy with and without CoT on a representative sample before adding it to a production prompt.
How long should the reasoning chain be? The model determines this based on task complexity. If chains are too verbose, add: "Reason concisely in at most 100 words, then give your final answer." If chains are too short and skipping steps, add: "Show every step — do not skip intermediate calculations."
Can I use CoT for creative writing tasks? It is less natural there. CoT is most valuable for tasks where there is a correct answer. For creative tasks, it can help with planning ("outline the story structure first, then write") but may constrain rather than help if applied too rigidly to open-ended generation.
What is the difference between CoT and scratchpad prompting?
Minimal in practice. Scratchpad prompting explicitly labels the working area — <scratchpad> or <thinking> — which makes it easier to parse and separate reasoning from the final answer. CoT is the general technique; scratchpad is a formatting convention for it. Anthropic's Claude models use extended thinking, which is a model-level implementation of the same idea.
When should I use self-consistency instead of basic CoT? Use self-consistency when: the task has a single objectively correct answer, your accuracy requirements are very high (medical, legal, financial decisions), and you can absorb the 3-5x API cost. For most production applications, basic zero-shot CoT is the right trade-off between accuracy and cost.
Does CoT work with Anthropic Claude differently than OpenAI models? The technique is identical — add the trigger phrase to the prompt. Claude models tend to produce more verbose reasoning chains by default. Claude also has an extended thinking feature (configurable via API) that runs a longer internal reasoning pass before the response. For standard CoT, the prompting approach is the same across providers.