AI Agent Evaluation: Catch Failures Before Production (2026)
Last updated: March 2026
How to Evaluate AI Agents: Metrics, Frameworks & Testing Patterns (2026)
Shipping an agent without evaluation is like deploying an API endpoint without monitoring. It works until it does not, and when it stops working you have no idea why, when it started breaking, or how often it was giving wrong answers before you noticed. Evaluation is not optional for production agent systems. It is what makes the difference between a system you can improve and one you can only replace.
Agent evaluation is harder than LLM evaluation for a structural reason: the output of an agent is not a single response, it is a trajectory of actions and observations leading to a final answer. A wrong final answer might result from one bad tool call in step 3, from poor planning in step 1, or from a correct but misinterpreted observation in step 7. To improve the agent, you need to know which part failed.
This post covers the metrics that matter, how to build a lightweight evaluation harness, and how to use LangSmith for production tracing.
Concept Overview
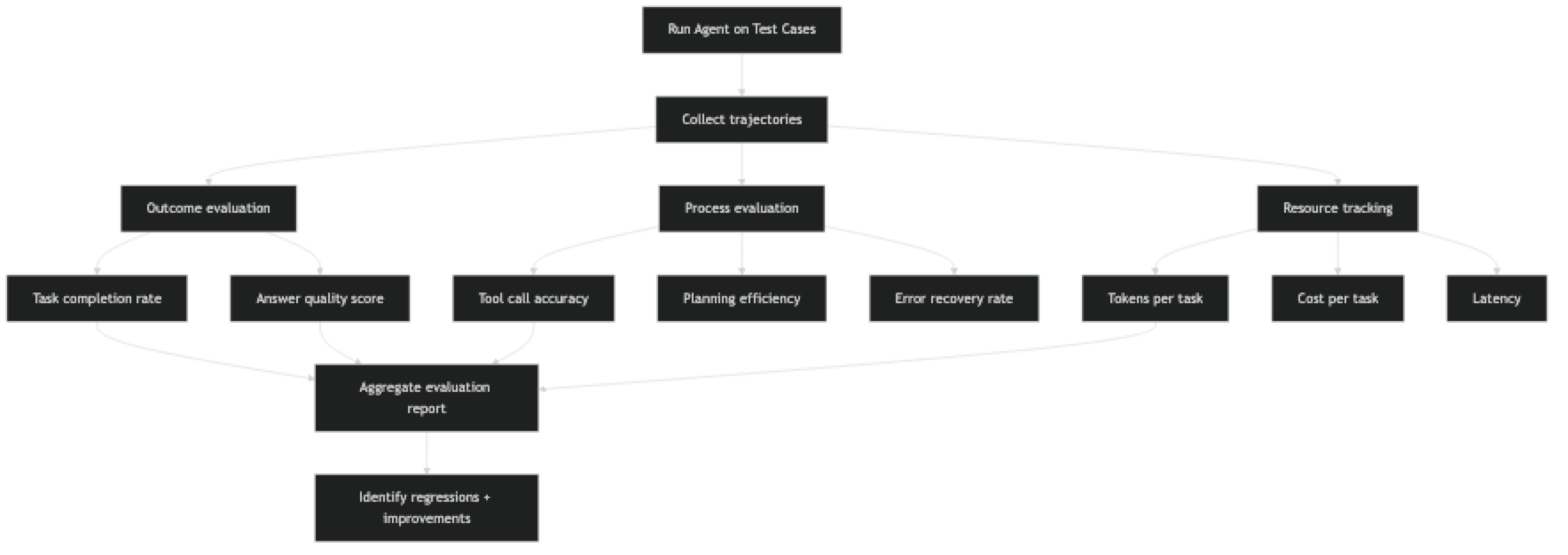
Agent evaluation splits into four dimensions:
Outcome metrics — Did the agent complete the task correctly? This is the most important dimension but also the hardest to measure automatically. Task completion rate and answer quality fall here.
Process metrics — How well did the agent plan and execute? Tool call accuracy, planning quality, and step efficiency fall here.
Resource metrics — How much did the agent cost to run? Token usage, API calls, latency, and cost per task are measured here.
Reliability metrics — How consistently does the agent perform? Error rate, retry rate, and variance across runs are measured here.
Most agent problems show up in process or reliability metrics before they become visible in outcome metrics. If tool call accuracy is dropping, final answer quality will follow. Catching it early requires measuring all four dimensions.
How It Works
Implementation Example
Step 1: Define Test Cases
from dataclasses import dataclass, field
from typing import Optional, Callable
@dataclass
class AgentTestCase:
"""A single test case for agent evaluation."""
id: str
task: str
expected_tools: list[str] = field(default_factory=list) # Tools that SHOULD be called
forbidden_tools: list[str] = field(default_factory=list) # Tools that should NOT be called
expected_keywords: list[str] = field(default_factory=list) # Keywords expected in output
max_steps: int = 10
max_cost_usd: float = 0.50
validator: Optional[Callable] = None # Custom validation function
# Define a test suite
research_agent_tests = [
AgentTestCase(
id="test_001",
task="What is the current Python version and when was it released?",
expected_tools=["web_search"],
expected_keywords=["python", "3.", "release"],
max_steps=5,
max_cost_usd=0.10
),
AgentTestCase(
id="test_002",
task="Calculate the compound interest on $10,000 at 5% annual rate for 3 years",
expected_tools=["python_repl"],
forbidden_tools=["web_search"], # Should not need to search for this
expected_keywords=["11576", "$11,576", "11,576.25"], # Expected numeric result
max_steps=3,
max_cost_usd=0.05
),
AgentTestCase(
id="test_003",
task="What are the three main differences between LangGraph and LangChain?",
expected_tools=["web_search", "wikipedia"],
expected_keywords=["langgraph", "langchain", "state"],
max_steps=8,
max_cost_usd=0.30
),
AgentTestCase(
id="test_004",
task="Research quantum computing and write a 200-word summary",
expected_tools=["web_search"],
max_steps=8,
max_cost_usd=0.40,
validator=lambda output: len(output.split()) >= 150 # At least 150 words
),
]Step 2: Evaluation Harness
from langchain.agents import AgentExecutor
from datetime import datetime
import json
@dataclass
class EvaluationResult:
"""Result of evaluating one test case."""
test_id: str
task: str
status: str # "passed" | "failed" | "error"
output: str
tools_called: list[str]
steps_taken: int
tokens_used: int
cost_usd: float
latency_seconds: float
failures: list[str]
class AgentEvaluator:
"""Runs agent test cases and computes evaluation metrics."""
def __init__(self, agent_executor: AgentExecutor, token_cost_per_1k: float = 0.005):
self.executor = agent_executor
self.token_cost_per_1k = token_cost_per_1k
def run_test_case(self, test: AgentTestCase) -> EvaluationResult:
"""Run a single test case and evaluate the result."""
start_time = datetime.now()
failures = []
try:
result = self.executor.invoke(
{"input": test.task},
config={"run_name": test.id} # For LangSmith tracing
)
elapsed = (datetime.now() - start_time).total_seconds()
output = result.get("output", "")
intermediate = result.get("intermediate_steps", [])
# Extract tools called
tools_called = [action.tool for action, _ in intermediate]
steps_taken = len(intermediate)
# Rough token estimation from output length
estimated_tokens = len(output.split()) * 1.3 + steps_taken * 500
cost_usd = (estimated_tokens / 1000) * self.token_cost_per_1k
# Check expected tools were called
for expected_tool in test.expected_tools:
if expected_tool not in tools_called:
failures.append(f"Expected tool not called: {expected_tool}")
# Check forbidden tools were not called
for forbidden_tool in test.forbidden_tools:
if forbidden_tool in tools_called:
failures.append(f"Forbidden tool was called: {forbidden_tool}")
# Check expected keywords in output
output_lower = output.lower()
for keyword in test.expected_keywords:
if keyword.lower() not in output_lower:
failures.append(f"Expected keyword missing from output: '{keyword}'")
# Check step limit
if steps_taken > test.max_steps:
failures.append(f"Exceeded max steps: {steps_taken} > {test.max_steps}")
# Check cost limit
if cost_usd > test.max_cost_usd:
failures.append(f"Exceeded cost limit: ${cost_usd:.3f} > ${test.max_cost_usd}")
# Run custom validator
if test.validator and not test.validator(output):
failures.append("Custom validator returned False")
status = "passed" if not failures else "failed"
return EvaluationResult(
test_id=test.id,
task=test.task,
status=status,
output=output,
tools_called=tools_called,
steps_taken=steps_taken,
tokens_used=int(estimated_tokens),
cost_usd=round(cost_usd, 4),
latency_seconds=round(elapsed, 2),
failures=failures
)
except Exception as e:
elapsed = (datetime.now() - start_time).total_seconds()
return EvaluationResult(
test_id=test.id,
task=test.task,
status="error",
output="",
tools_called=[],
steps_taken=0,
tokens_used=0,
cost_usd=0.0,
latency_seconds=round(elapsed, 2),
failures=[f"Exception: {str(e)}"]
)
def run_suite(self, test_cases: list[AgentTestCase]) -> dict:
"""Run all test cases and produce an evaluation report."""
results = []
print(f"\nRunning {len(test_cases)} test cases...\n")
for test in test_cases:
print(f" [{test.id}] {test.task[:60]}...")
result = self.run_test_case(test)
results.append(result)
status_icon = "PASS" if result.status == "passed" else "FAIL" if result.status == "failed" else "ERR"
print(f" [{status_icon}] Steps: {result.steps_taken}, Cost: ${result.cost_usd:.3f}, Latency: {result.latency_seconds}s")
if result.failures:
for failure in result.failures:
print(f" - {failure}")
return self._compute_metrics(results)
def _compute_metrics(self, results: list[EvaluationResult]) -> dict:
"""Compute aggregate metrics from test results."""
total = len(results)
if total == 0:
return {}
passed = sum(1 for r in results if r.status == "passed")
failed = sum(1 for r in results if r.status == "failed")
errors = sum(1 for r in results if r.status == "error")
successful = [r for r in results if r.status == "passed"]
all_completed = [r for r in results if r.status != "error"]
metrics = {
"summary": {
"total_tests": total,
"passed": passed,
"failed": failed,
"errors": errors,
"pass_rate": round(passed / total * 100, 1),
},
"performance": {
"avg_steps": round(sum(r.steps_taken for r in all_completed) / max(len(all_completed), 1), 1),
"avg_latency_seconds": round(sum(r.latency_seconds for r in all_completed) / max(len(all_completed), 1), 1),
"avg_cost_usd": round(sum(r.cost_usd for r in all_completed) / max(len(all_completed), 1), 4),
"total_cost_usd": round(sum(r.cost_usd for r in results), 4),
},
"failures": {
result.test_id: result.failures
for result in results
if result.failures
}
}
return metricsStep 3: LangSmith Integration
LangSmith provides production-grade tracing for LangChain agents. Every tool call, reasoning step, and token count is captured automatically.
import os
# Set up LangSmith (set these environment variables)
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "your-langsmith-api-key"
os.environ["LANGCHAIN_PROJECT"] = "my-agent-production" # Project name in LangSmith
# With these env vars set, all agent runs are automatically traced
# No code changes required in your agent
# You can also add explicit metadata to traces
from langchain_core.tracers.context import tracing_v2_enabled
with tracing_v2_enabled(project_name="agent-evaluation"):
result = executor.invoke(
{"input": "What is the best AI agent framework in 2026?"},
config={
"run_name": "test_evaluation_run",
"tags": ["evaluation", "v1.2.0"],
"metadata": {
"test_id": "test_001",
"environment": "staging",
"agent_version": "1.2.0"
}
}
)Step 4: Run the Evaluation
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain_community.tools import DuckDuckGoSearchRun
from langchain_experimental.tools import PythonREPLTool
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# Build your agent
llm = ChatOpenAI(model="gpt-4o", temperature=0)
tools = [
DuckDuckGoSearchRun(name="web_search"),
PythonREPLTool(name="python_repl")
]
prompt = ChatPromptTemplate.from_messages([
("system", "You are a research assistant. Use tools to answer questions accurately."),
("human", "{input}"),
MessagesPlaceholder("agent_scratchpad"),
])
agent = create_tool_calling_agent(llm=llm, tools=tools, prompt=prompt)
executor = AgentExecutor(
agent=agent,
tools=tools,
max_iterations=10,
handle_parsing_errors=True,
return_intermediate_steps=True
)
# Run evaluation
evaluator = AgentEvaluator(executor)
metrics = evaluator.run_suite(research_agent_tests)
# Print report
print("\n" + "="*60)
print("EVALUATION REPORT")
print("="*60)
print(json.dumps(metrics, indent=2))Best Practices
Build evaluation before you build the agent. Writing test cases first forces you to specify what "correct" looks like before you are attached to a particular implementation. This produces clearer requirements and better test coverage.
Evaluate on diverse task types. A test suite of similar tasks will not reveal edge cases. Include simple tasks, complex multi-step tasks, tasks where tools return errors, and tasks where the correct answer is "I cannot find this information."
Measure regression across versions. Store evaluation results with version metadata. Every time you change the agent (model upgrade, prompt change, new tool), run the full suite and compare. Regressions in pass rate or cost metrics indicate problems.
Use both automated and human evaluation. Automated metrics catch structural failures (wrong tool called, missing keywords). Human evaluation catches quality failures (correct answer but poorly explained, relevant answer but incomplete). Both are necessary.
Common Mistakes
Measuring only the final answer, not the trajectory. An agent can reach a correct answer via a wrong path — excessive tool calls, incorrect intermediate reasoning, expensive detours. Trajectory evaluation catches problems that outcome evaluation misses.
Test cases that are too similar. A test suite of ten variations on the same type of question will give you false confidence. Diversify across task types, difficulty levels, and tool requirements.
Not testing failure scenarios. Test what happens when a tool returns an error, when search results are empty, or when the task is ambiguous. Agents should handle these gracefully, not crash or hallucinate.
Running evaluation only before deployment. Production behavior can drift as models are updated, tool APIs change, or data sources evolve. Run evaluation continuously against a held-out test set in production.
Treating evaluation cost as an afterthought. Running 50 test cases with GPT-4o at 10 iterations each costs real money. Budget for evaluation, use cheaper models for automated test runs, and save expensive model evaluation for release candidates.
Key Takeaways
- Use
create_tool_calling_agent(not deprecatedcreate_openai_functions_agent) for all new agent code - Agent evaluation has four dimensions: outcome (did it complete the task?), process (did it use the right tools?), resource (how much did it cost?), and reliability (how consistent is it?)
- Build the test suite before building the agent — writing test cases first forces you to define what "correct" looks like
- Evaluate the trajectory, not just the final answer — a correct answer via an inefficient or incorrect path indicates a real problem
- Minimum 20-30 diverse test cases covering: happy path, tool failures, edge cases, out-of-scope tasks, and multi-tool chains
- Use
run_name,tags, andmetadatain the LangSmith config to make traces filterable in production - Run evaluation continuously in production, not just before deployment — model updates, API changes, and data drift cause behavior to change
- Budget for evaluation cost — 50 test cases at GPT-4o with 10 iterations each is non-trivial; use cheaper models for routine CI evaluation
FAQ
What is a good pass rate for an agent evaluation suite? For production agents handling real user tasks, aim for 85%+ on your core test suite. Below 80% generally indicates fundamental problems with planning or tool reliability. 95%+ is achievable for well-defined, narrow tasks. For complex, open-ended research tasks, 75-80% may be realistic given inherent task ambiguity.
How many test cases do I need? A minimum of 20-30 test cases covering your primary task types. 50-100 is better for a system in production. The cases should cover: normal tasks, edge cases, tasks where tools fail, tasks requiring multiple tools, and tasks that should produce "I do not know" answers.
Can I use an LLM to evaluate an LLM agent? Yes — this is called LLM-as-judge. Use a more capable model (or the same model with an evaluation rubric) to score agent outputs on criteria like factual accuracy, completeness, and tool selection quality. This scales better than human evaluation but introduces its own biases. Always calibrate LLM-judge scores against human ratings on a sample before relying on them at scale.
What is LangSmith and is it required for production? LangSmith is a tracing and observability platform for LangChain-based agent systems. It captures complete execution traces, token usage, and latency with zero code changes when the environment variables are set. It is not required but significantly accelerates debugging. Open-source alternatives include Langfuse and Phoenix (Arize).
How do I handle non-deterministic agent outputs in evaluation? Run each test case multiple times (3-5 runs) and use aggregate statistics rather than single-run pass/fail. For outputs that vary by design (open-ended research), evaluate on structural criteria — contains required sections, minimum word count, does not hallucinate known facts — rather than exact output matching.
What is trajectory evaluation and why does it matter? Trajectory evaluation analyzes the sequence of tool calls and observations an agent makes on the path to its final answer. A correct final answer via an inefficient trajectory (too many steps, wrong tools called first) signals a problem that will worsen as tasks scale in complexity. Trajectory metrics include: tools called vs. expected tools, step count vs. minimum viable step count, and tool call accuracy rate.
How do I evaluate an agent that writes to external systems? Use a sandbox environment with mock versions of external systems (test database, mock email server, dry-run API mode). Evaluate that the agent called the right endpoints with the right parameters without actually executing side effects. For irreversible actions (emails, payments), human-in-the-loop evaluation is required — never run these in automated eval against production systems.